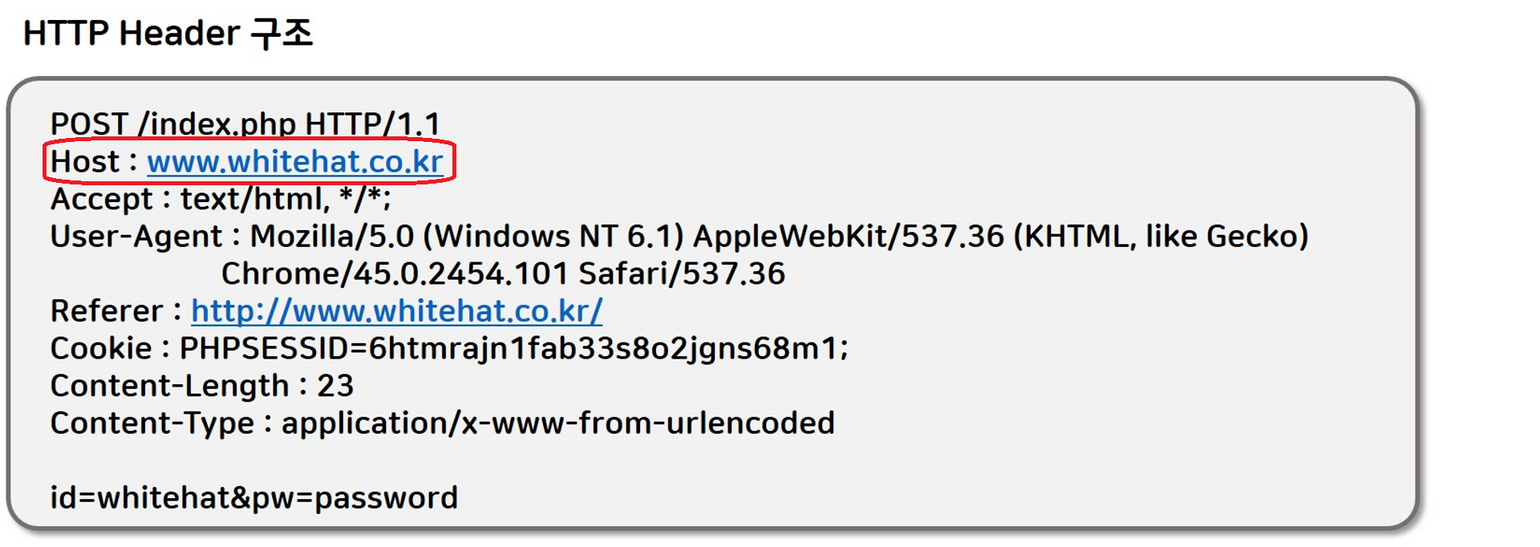
서블릿이란 ❓
서블릿(Servlet)은 자바를 사용하여 웹 애플리케이션을 개발하기 위한 기술로, 웹 서버와 상호작용하여 동적인 웹 페이지를 생성하고 처리하는 자바 클래스입니다. 서블릿은 웹 서버에서 실행되며, 클라이언트의 요청에 따라 동적인 컨텐츠를 생성하여 응답으로 제공하는 역할을 수행합니다.
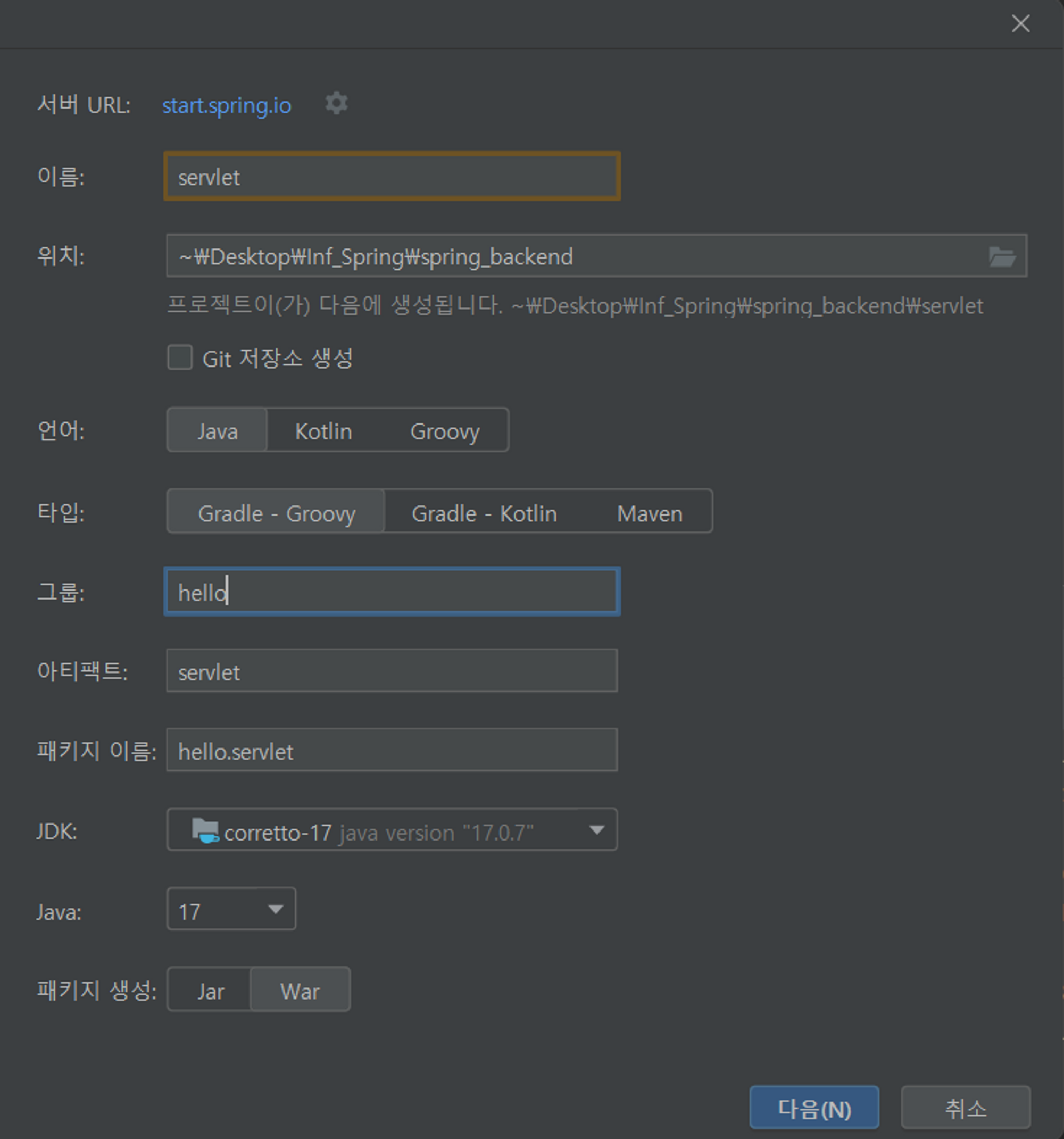

해당 버전과 종속성들을 추가한 후 프로젝트 파일을 생성 후 실행합니다. 내부의 톰캣 서버와 외부에서 불러온 서버를 실행할 수 있도록 패키지 생성은 War로 선택한 후 생성하면 됩니다.

Dependcy들이 설치된 사항을 볼 수 있는 build.gradle로 접속하여 plugins항목에 war로 생성이 잘 진행되었는지 확인해주세요
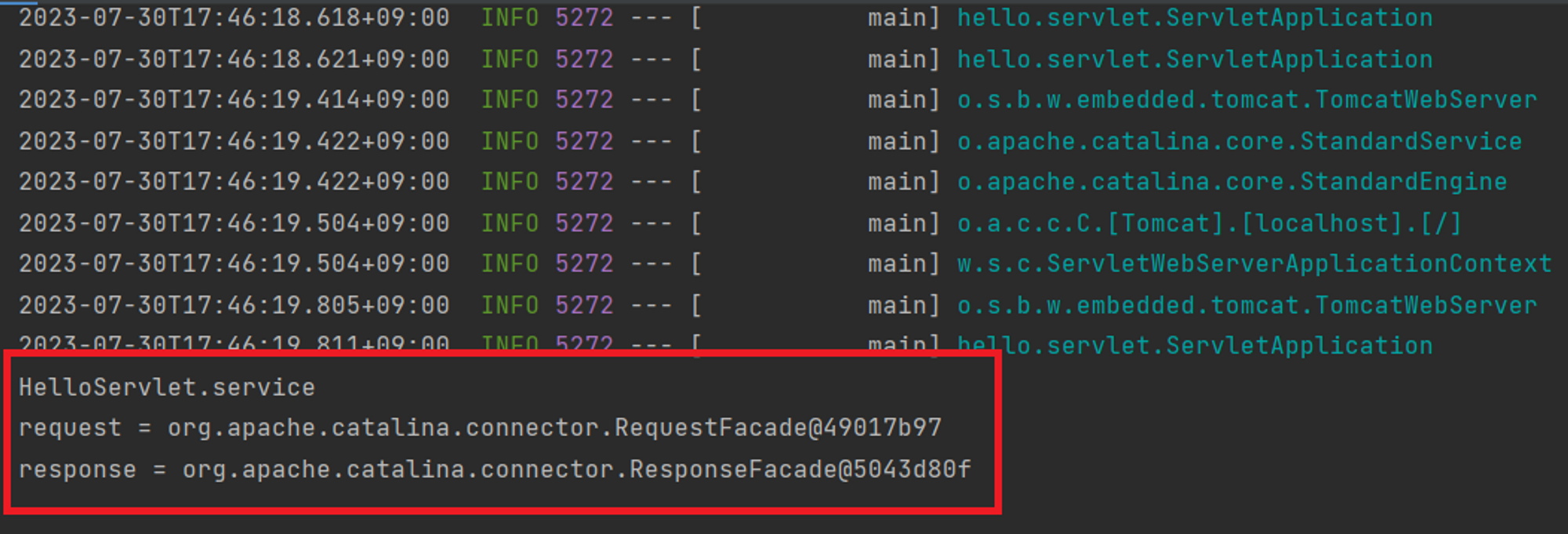

📋HTTPServletRequest
HttpServletRequest는 Java Servlet에서 HTTP 요청 정보를 담고 있는 객체입니다. 클라이언트가 서버로 HTTP 요청을 보낼 때, 이 HttpServletRequest 객체를 통해 요청의 다양한 정보를 서블릿에 전달합니다.
📋 HttpServletResponse
Java Servlet에서 HTTP 응답을 다루는 객체입니다. 클라이언트에게 서버로부터 전달되는 HTTP 응답을 생성하고 제공하는데 사용됩니다. 서블릿은 클라이언트의 요청을 받아 처리한 후, 이 HttpServletResponse 객체를 사용하여 적절한 응답을 생성하고 클라이언트에게 반환합니다.
HTTP 요청 메세지 전달 방법 - HttpServletRequest 기본 사용법
- GET - 쿼리 파라미터
- 쿼리 파라미터는 URL에 다음과 같이 ? 를 시작으로 보낼 수 있습니다.
- 여러 개의 파라미터를 전달할 경우 & 기호로 구분합니다. 검색,필터,페이징에서 많이 사용
- 예: http://example.com/api/data?key1=value1&key2=value2
/**
* 1. 파라미터 전송 기능
* http://localhost:8080/request-param?username=hello&age=20*/
@WebServlet(name="requestParamServlet", urlPatterns = "/request-param")
public class RequestParamServlet extends HttpServlet {
@Override
protected void service(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException {
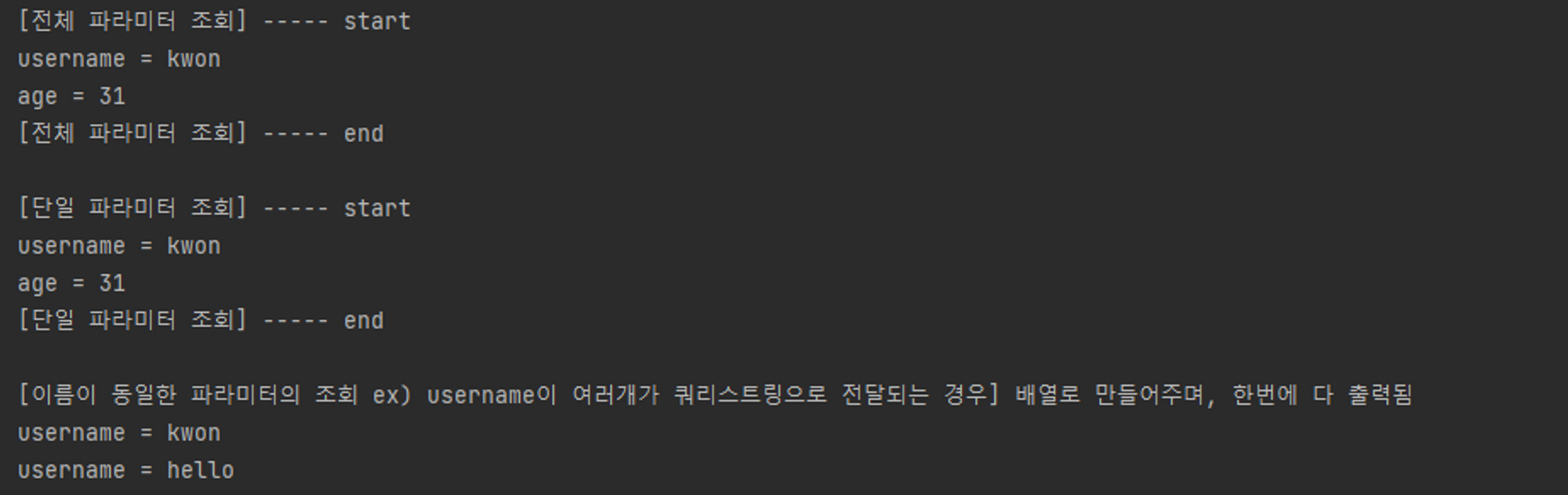
System.out.println("[전체 파라미터 조회] ----- start");
req.getParameterNames().asIterator().forEachRemaining(paramName -> System.out.println(paramName + " = " + req.getParameter(paramName)));
System.out.println("[전체 파라미터 조회] ----- end");
System.out.println();
System.out.println("[단일 파라미터 조회] ----- start");
String username = req.getParameter("username");
String age = req.getParameter("age");
System.out.println("username = " + username);
System.out.println("age = " + age);
System.out.println("[단일 파라미터 조회] ----- end");
System.out.println();
System.out.println("[이름이 동일한 파라미터의 조회 ex) username이 여러개가 쿼리스트링으로 전달되는 경우] 배열로 만들어주며, 한번에 다 출력됨");
String[] usernames = req.getParameterValues("username");
for (String name : usernames) {
System.out.println("username = " + name);
}
2. POST - HTML Form
- HTML Form 을 사용해서 클라이언트에서 서버로 데이터 전송이 가능합니다.
- contenty-type : application/x-www.form-urlencoded
- 메세지 바디에 쿼리 파라미터 형식으로 전달 username=hello&age=20 예) 회원 가입, 상품 주문, HTML Form 사용

GET 방식일 때 사용했던 쿼리파라미터 형식이랑 HTML Form 방식은 유사합니다. Content-type이 적히는 것의 차이만 있지 형식이 같기 때문에 request.getParameter로 HTML Form 방식으로 전송된 데이터 조회 메서드를 그대로 사용하는 것이 가합니다.
클라이언트(웹 브라우저) 입장에서는 두 방식에 차이가 있지만, 서버 입장에서는 둘의 형식이 동일하므로, request.getParameter() 로 편리하게 구분없이 조회할 수 있습니다.

3. HTTP message body에 데이터를 직접 담아서 요청 (API 메세지 바디)
- HTTP API에서 주로 사용하며, HTTP POST, PUT, PATCH 등의 요청 메서드를 사용하여 요청 본문에 데이터를 포함하여 전달합니다.
- 주로 JSON 또는 XML 형식으로 데이터를 포함합니다.
- 가장 먼저 단순한 텍스트 메세지를 HTTP 메세지 바디에 담아서 전송하고 읽어보겠습니다. HTTP 메세지 바디의 데이터를 InputStream을 사용해서 직접 읽을 수 있습니다.
👉 JSON 형식으로 데이터를 주고받는 방법 (HTTP API 에서 주로 사용)
JSON 형식으로 데이터를 주고받으려면 우선 JSON 형식으로 변경할 수 있는 객체를 하나 생성하겠습니다. 새로운 클래스파일을 하나 만든 후 멤버변수를 작성해주고, Lombok을 이용해 Getter와 Setter를 생성해줍니다.
/**
* http://localhost:8080/request-body-json
*
* JSON 형식 전송
* content-type: application/json
* message body: {"username": "hello", "age": 20}
*
*/
@WebServlet(name = "requestBodyJsonServlet", urlPatterns = "/request-body-json")
public class RequestBodyJsonServlet extends HttpServlet {
private ObjectMapper objectMapper = new ObjectMapper();
@Override
protected void service(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
ServletInputStream inputStream = request.getInputStream();
String messageBody = StreamUtils.copyToString(inputStream,
StandardCharsets.UTF_8);
System.out.println("messageBody = " + messageBody);
HelloData helloData = objectMapper.readValue(messageBody,HelloData.class);
System.out.println("helloData.username = " + helloData.getUsername());
System.out.println("helloData.age = " + helloData.getAge());
response.getWriter().write("ok");
}
}

'[ BACKEND] > Spring' 카테고리의 다른 글
| [SPRING] Servlet / JSP / MVC (0) | 2023.08.04 |
|---|---|
| [SPRING] Storage (저장소) & URL 패턴 (0) | 2023.08.03 |
| [SPRING] Web Application (0) | 2023.07.31 |
| [SPRING] 싱글톤 방식의 주의점 💥 (0) | 2023.07.25 |
| [SPRING] Web Application과 Singleton의 관계 (0) | 2023.07.24 |