Redirect와 Forward는 웹 애플리케이션에서 페이지 간의 이동을 처리하는 방법입니다. 특정 URL 접속 시 Redirect 또는 Foward가 발생하면 작업 중인 페이지가 전환됩니다. 각각의 방식은 다음과 같은 특징을 가지고 있습니다
Redirect: 서버에서 클라이언트에서 요청한 URL에 대한 응답에서 다른 URL로 재 접속하라고 명령을 보내는 것을 말합니다. Re-Direct가 발생하면 ‘URL을 다시 가리킨다’ 라는 뜻으로 URL 주소가 바뀌면서 다시 접속되는 것을 확인할 수 있습니다.
클라이언트의 요청을 받은 서버가 클라이언트에게 다른 URL로 재요청하도록 응답합니다. 클라이언트는 새로운 URL로 다시 요청을 보내고, 이에 대한 응답을 받습니다.
서버 간의 완전히 새로운 요청이기 때문에, 클라이언트에게는 이전 요청과 다른 URL이 표시됩니다. 주로 로그인 후에 리다이렉션을 사용하여 다른 페이지로 이동하거나, POST 요청 후에 브라우저의 새로고침을 방지하기 위해 사용됩니다.
https://kotlinworld.com/329#google_vignette
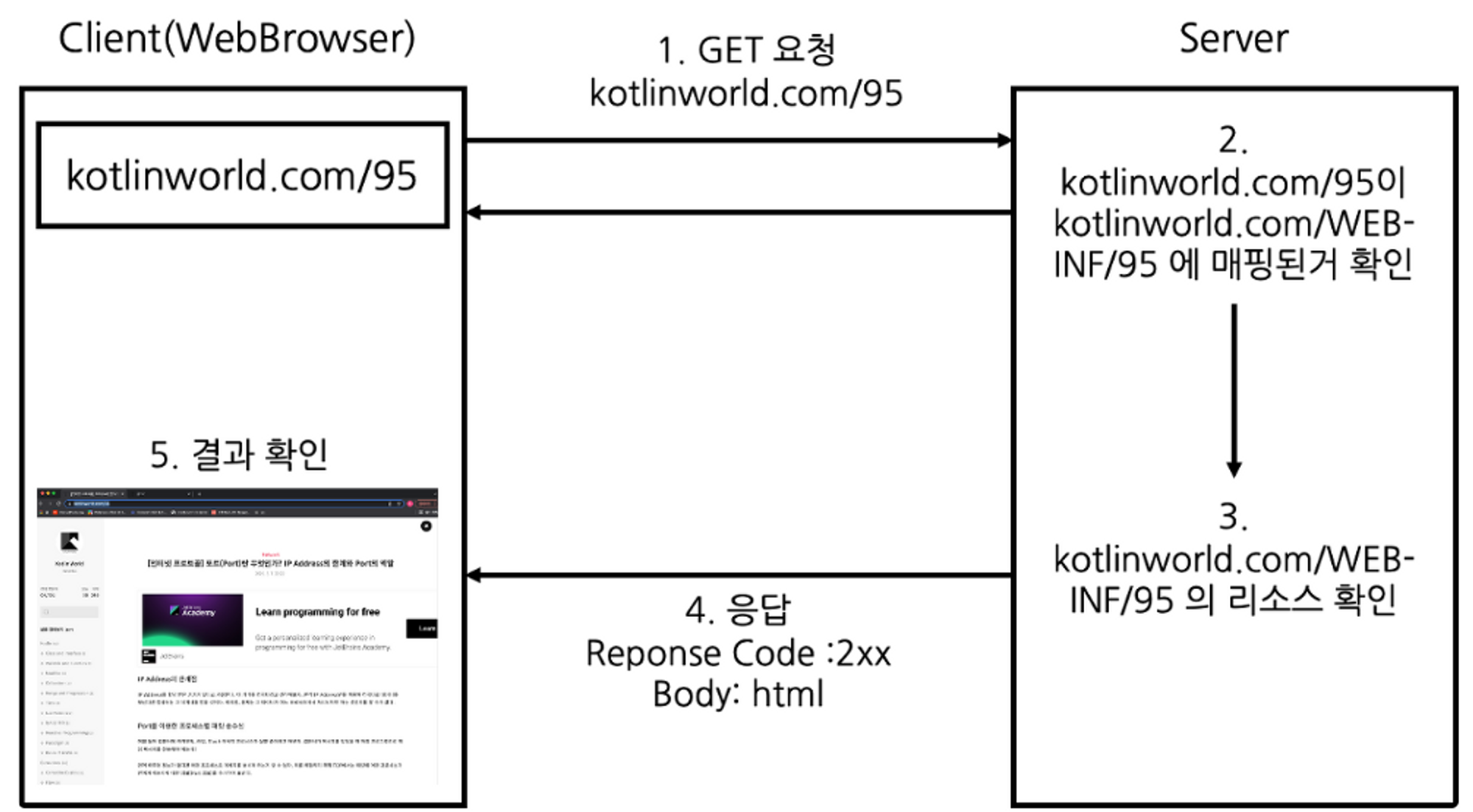
2. Forward: 서버 내부에서 일어나는 호출이며, 클라이언트의 URL에 대한 요청이 들어오면 해당 URL이 다른 URL로 포워딩 된 것이 확인 되었을 경우 서버에서 포워딩된 URL의 리소스를 확인하여 클라이언트에게 응답합니다.
서버 내에서 페이지를 전환하며, 클라이언트는 이 과정을 인식하지 못합니다. 서버에서 다른 페이지로 요청을 전달하고, 이에 대한 응답을 클라이언트에게 직접 반환합니다.
클라이언트는 서버 간의 전환 과정을 인지하지 못하고, 이전 URL이 유지됩니다. 주로 서버 내부에서의 페이지 간의 이동이 필요한 경우에 사용됩니다.
https://kotlinworld.com/329#google_vignette
일반적으로, Redirect는 클라이언트의 요청을 완전히 새로운 URL로 전달하여 처리하는 방식입니다. 클라이언트는 새로운 URL로 다시 요청하고, 서버는 이에 대한 응답을 처리합니다. 반면, Forward는 서버 내에서 페이지를 전환하는 방식으로, 클라이언트는 이 과정을 인식하지 못하고 이전 URL이 유지됩니다.
RedirectView를 사용하면 스프링 MVC 컨트롤러에서 리다이렉트를 처리할 수 있습니다. RedirectView는 스프링 프레임워크에서 제공하는 클래스로, 리다이렉트를 수행하기 위해 사용됩니다.
forward의 예시 ex)은행에서 1년치 입출력 내역을 출력하고 싶을 때, download 요청시! download type은 pdf인 상황
@RequestMapping("/download")
public String download(HttpServletRequest request, @RequestParam(required=false, defaultValue="") String type) {
List<User> userList = getUserList();
request.setAttribute("data", userList); // request에 저장하면, forward 된 곳에서 사용 가능
if(type.equals("pdf") {
return "forward:/pdfView";
} else if (type.equals("csv")) {
return "forward:/csvView";
}
return "forward:/txtView";
}
Java 언어를 사용하여 웹 애플리케이션을 개발하기 위한 서버 측 컴포넌트입니다. 웹 서버와 상호작용하여 동적인 웹 페이지를 생성하고 클라이언트 요청에 응답하는 역할을 합니다. 서블릿은 Java Servlet API에 정의된 규칙에 따라 작성되며, 웹 애플리케이션 서버에서 실행됩니다.
WebServlet = @Controller + @RequestMapping입니다. 서블릿에서는 service 메서드가 고정이고 , 매개변수로 request와 response를 받습니다. IOException하여 예외를 던지게 되는데, PrintWriter로 out.println을 사용할 때 발생하는 예외를 위해 작성하게됩니다.
@Controller와 @RequestMapping을 사용하게되면 상속을 받지 않아도 되고 애너테이션도 나눠서 처리함으로써 코드가 간결해질 수 있습니다.
👉 서블릿의 생명주기
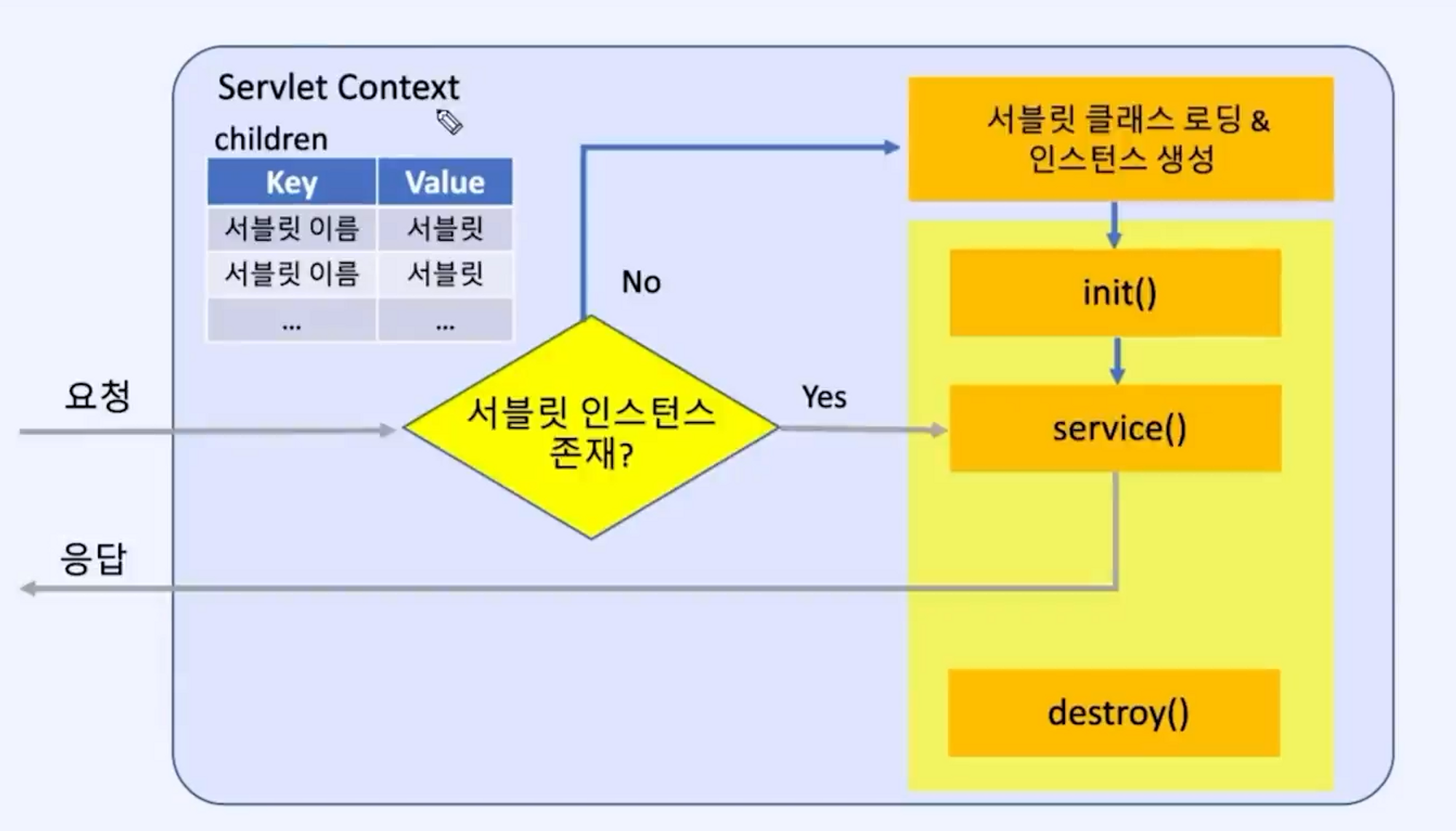
서블릿의 생명주기(Lifecycle)는 서블릿 인스턴스의 생성부터 소멸까지의 단계를 의미합니다. 서블릿은 클라이언트의 요청에 따라 반복적으로 생성되고 처리되는데, 이러한 과정은 다음과 같은 단계로 이루어집니다
초기화(Initialization): 서블릿 인스턴스의 생성과 동시에 초기화 작업이 수행됩니다. 이 단계에서는init() 메서드가 호출되며, 서블릿이 필요로 하는 리소스를 초기화하고 설정합니다. 초기화는 서블릿의 라이프사이클 동안 한 번만 수행됩니다.
서비스(Service): 서블릿이 클라이언트의 요청을 처리하는 주요 단계입니다. 클라이언트가 HTTP 요청을 보내면, 웹 컨테이너는 해당 요청을 처리하기 위해 service() 메서드를 호출합니다. service() 메서드는 요청의 HTTP 메서드(GET, POST 등)에 따라 적절한 메서드(doGet(), doPost() 등)를 호출하여 요청을 처리합니다.
요청 처리: service() 메서드 내에서는 클라이언트의 요청을 처리하고, 동적인 콘텐츠를 생성합니다. 이 단계에서는 사용자가 정의한 비즈니스 로직을 구현하고 데이터베이스 조회, 파일 업로드 등의 작업을 수행합니다.
소멸(Destruction): 서블릿의 인스턴스가 더 이상 필요하지 않을 때, 웹 컨테이너는 해당 인스턴스를 소멸시킵니다. 이 단계에서는 distroy() 메서드가 호출되며, 서블릿이 사용한 리소스를 정리하고 마무리 작업을 수행합니다. 소멸은 서블릿의 라이프사이클 동안 한 번만 수행됩니다.
@WebServlet("/hello")
public class HelloServlet extends HttpServlet{
//서블릿이 초기화 될 때 자동 호출되는 메서드
//1. 서블릿의 초기화 작업을 담당
@Override
public void init() throws ServletException {
System.out.println("[HelloServlet] init() 메서드가 호출되었습니다.");
super.init();
}
@Override
protected void service(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
//1. 입력 2. 처리 3. 출력
System.out.println("[HelloServlet] service() 메서드가 호출되었습니다.");
super.service(req, resp);
}
@Override
public void destroy() {
System.out.println("[HelloServlet] destroy() 메서드가 호출되었습니다.");
}
}
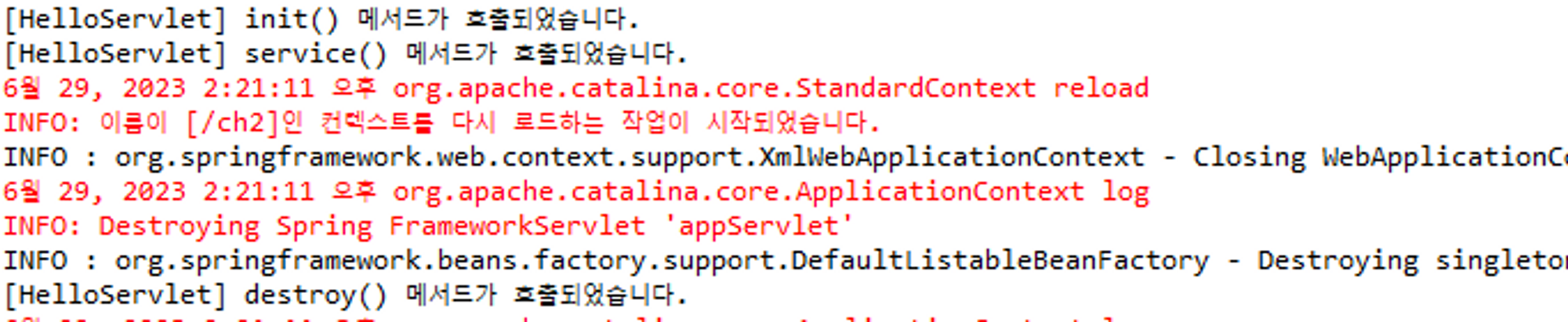
서버를 실행한 후 localhost:8080/ch2/hello로 접속하면 아래의 문장이 출력되고 , 보이는 것과 같이 init() 메서드는 맨처음에 제일 먼저 한번 실행되고 이후 새로고침하여 로딩을 반복하면 service() 메서드만 호출되는 것을 볼 수 있습니다.
JSP란 ?
JSP(JavaServer Pages)는 Java 언어를 기반으로 하는 서버 측 웹 프로그래밍 기술입니다. JSP는 동적인 웹 페이지를 생성하기 위한 스크립트 기반의 웹 템플릿 엔진입니다. JSP는 HTML 코드와 Java 코드를 결합하여 웹 페이지를 생성하는데 사용됩니다.
JSP는 HTML 문서 안에 Java 코드를 삽입하여 웹 페이지의 동적인 부분을 처리할 수 있습니다. JSP 파일은 서블릿으로 변환되어 실행되며, 실행 시에는 동적인 콘텐츠를 생성하고 웹 브라우저로 전송합니다. JSP로 작성을 하면 자동으로 서블릿으로 변환됩니다. JSP는 HTML안에 java 코드가 있는 것이라고 생각하면 됩니다. <% 이런 태그 java코드 작성이 가능합니다 %>
*.jsp (jsp 요청) 요청이 들어오면 JspServle이 다 받는데 받은 후 서블릿 인스턴스가 오는지 확인합니다. 이후 서블릿 소스파일을 변환하고 클래스파일로 컴파일 합니다.
Jsp에는 기본객체가 있는데 기본 객체는 생성 없이 사용할 수 있는 객체를 의미합니다.
request: 클라이언트의 요청에 관련된 정보를 담고 있는 객체입니다. 폼 데이터, URL 매개변수, HTTP 헤더 등의 정보를 읽거나 설정할 수 있습니다.
response: 서버가 클라이언트로 응답을 보내기 위한 기능을 제공하는 객체입니다. 응답의 상태, 헤더, 콘텐츠 등을 설정할 수 있습니다.
session: 클라이언트와 서버 간의 세션을 관리하는 객체입니다. 세션 데이터를 저장하고 검색하는 데 사용됩니다. 여러 요청 간에 상태 정보를 유지하는 데 유용합니다.
application: 웹 애플리케이션 수준의 정보를 저장하고 액세스하는 데 사용되는 객체입니다. 웹 애플리케이션 전체에서 공유되는 데이터를 저장하는 데에 유용합니다.
out: 클라이언트로 출력할 데이터를 담는 출력 스트림 객체입니다. JSP 페이지에서 생성한 콘텐츠를 클라이언트에게 전송할 때 사용됩니다.
page: 현재 JSP 페이지를 나타내는 객체입니다. JSP 페이지 자체를 다루는 메서드나 속성에 액세스하는 데 사용됩니다.
config: JSP 페이지의 설정 정보를 포함하는 객체입니다. 웹 애플리케이션의 설정 정보에 액세스하는 데 사용됩니다.
exception: JSP 페이지에서 발생한 예외 정보를 담고 있는 객체입니다. 예외 처리 및 오류 페이지로의 전환에 사용될 수 있습니다.
이러한 기본 객체들은 JSP 페이지 내에서 자동으로 생성되고 사용할 수 있습니다. 예를 들어, request.getParameter("paramName")과 같은 방식으로 request 객체의 메서드를 호출하여 요청 매개변수의 값을 가져올 수 있습니다.
제어의 역전 Inversion of Control (IoC)는 소프트웨어 디자인 패턴 중 하나입니다. IoC는 제어의 역전이라고도 불리며, 객체 간의 의존성을 해결하기 위한 개념입니다.
기존 프로그램은 클라이언트 구현 객체가 스스로 필요한 서버 구현 객체를 생성하고, 연결하고, 실행합니다. 구현 객체가 프로그램의 제어 흐름을 스스로 조종하는 개념입니다. 반면, 역할과 구현을 분리하게되면 구현 객체는 자신의 로직을 실행하는 역할만 담당하기 때문에 프로그램 흐름을 구성 영역이 가져가게됩니다. 구성 영역이 프로그램 제어 흐름 대한 권한을 갖게 된다면 사용 영역의 클래스들은 필요한 인터페이스들은 호출하지만 어떤 구현객체들이 실행되는지는 알 수가 없습니다.
이러한 의존성을 해결하기 위해 제어의 흐름을 역전시키는 개념입니다. 기존에는 객체가 직접 의존하는 객체를 생성하고 관리하는 주체였지만, IoC에서는 객체가 직접 의존하는 객체를 생성하고 관리하는 책임을 외부 컨테이너 또는 프레임워크에게 위임합니다.
즉, IoC는 객체의 생명주기와 의존성 관리를 외부에 위임함으로써 코드의 결합도를 낮추고 유연성과 재사용성을 향상시킵니다. 이를 통해 소프트웨어의 확장성과 테스트 용이성을 개선할 수 있습니다.
IoC의 구현 방법으로는 의존성 주입(Dependency Injection)이 주로 사용됩니다. 의존성 주입은 객체가 필요로 하는 의존성을 외부에서 주입받는 방식으로 이루어집니다. 이를 통해 객체 간의 결합도를 줄이고 테스트하기 쉬운 코드를 작성할 수 있습니다.
의존성 주입(Dependency Injection, DI)은 객체 간의 의존 관계를 개발자가 직접 관리하지 않고, 외부에서 의존하는 객체를 주입하여 사용하는 디자인 패턴입니다. DI는 객체 간의 결합도를 낮추고 유연하고 재사용 가능한 코드를 작성할 수 있도록 도와줍니다.
일반적으로 객체 간의 의존 관계는 하나의 객체가 다른 객체를 생성하거나 참조하여 사용하는 것으로 나타납니다. 이러한 의존 관계는 코드 내에서 강한 결합도를 만들어내고, 객체의 생성과 관리를 담당하는 클래스가 다른 객체들에 대한 정보를 갖고 있어야 한다는 문제를 발생시킵니다. 이로 인해 코드의 유연성과 재사용성이 저하되는 문제가 발생할 수 있습니다.
DI는 이러한 문제를 해결하기 위해 의존하는 객체를 외부에서 주입하는 방식을 채택합니다. 주입된 객체는 해당 객체가 필요한 시점에 사용됩니다. 주로 생성자(Constructor) 주입, Setter 주입, 인터페이스 주입 등의 방식을 사용합니다.
DI의 주요 이점은 다음과 같습니다:
결합도 감소: 객체 간의 의존 관계를 외부에서 관리하기 때문에 객체들 간의 결합도가 낮아집니다. 이로 인해 하나의 객체 수정이 다른 객체에 미치는 영향을 최소화하고, 코드의 유지 보수성이 향상됩니다.
재사용성과 확장성: DI를 통해 의존하는 객체를 외부에서 주입받기 때문에 해당 객체의 변경 없이 쉽게 다른 객체와 조합하여 재사용하거나 기능을 확장할 수 있습니다.
테스트 용이성: 의존 객체를 모의(Mock) 객체로 대체하여 단위 테스트를 수행할 수 있습니다. 의존 객체의 동작을 외부에서 주입하여 테스트를 진행할 수 있기 때문에 테스트 용이성이 높아집니다.
Spring Framework는 DI를 통해 객체 간의 의존 관계를 관리하고 주입하는 기능을 제공합니다. 이를 통해 Spring에서는 객체 지향적인 애플리케이션을 개발할 수 있으며, 유연하고 확장 가능한 코드를 작성할 수 있습니다.
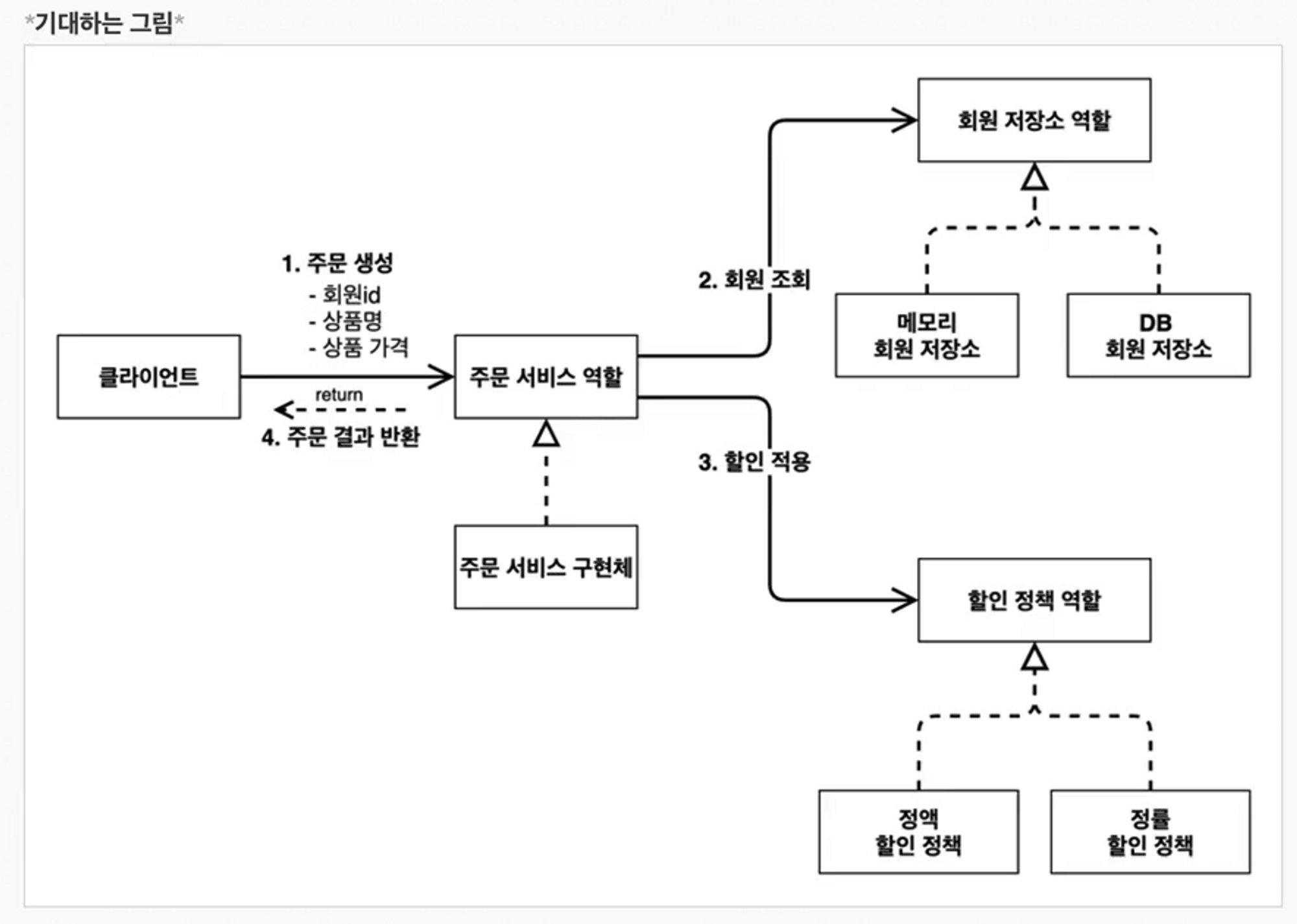
OrderServiceImple은 DiscountPolicy 인터페이스에 의존합니다. 실제 어떤 구현객체가 사용될지는 모르는 상황입니다. 의존관계는 “정적인 클래스 의존 관계와 실행 시점에 결정되는 동적인 객체(인스턴스) 의존 관계” 등을 분리해서 생각해야 합니다.
정적인 클래스 의존 관계 클래스가 사용하는 import 코드만 보고 의존관계를 쉽게 판단할 수 있습니다. 정적인 의존관계는 애플리케이션을 실행하지 않아도 분석할 수 있습니다. 클래스 다이어그램을 살펴보면 OrderServiceImpl은 MemberRepository, DiscountPolicy를 참조하고 있습니다. 이러한 클래스 의존관계 만으로는 실제 어떤 객체가 OrderServiceImpl에 주입되는 지 알기 어렵습니다.
동적인 객체 인스턴스 의존관계 AppConfig에서 OrderService()가 생성될 때 매개변수로 memberRepository()와 discountPolicy() 인스턴스를 담아주게 되는데, 인스턴스 다이어그램은 정적인 것이 아니라 애플리케이션 실행 시 동적으로 변하게 됩니다. 애플리케이션 “실행 시점(런타임)”에 외부에서 실제 구현 객체를 생성하고 클라이언트에 전달해서 클라이언트와 서버의 실제 의존관계가 연결되는 것을 “의존 관계 주입”이라고 합니다.의존 관계 주입을 사용하면 클라이언트 코드를 변경하지 않고 클라이언트가 호출하는 대상의 타입 인스턴스를 변경할 수 있습니다. 정적인 클래스 의존 관계를 변경하지 않고, 동적인 객체 인스턴스 의존관계를 쉽게 변경할 수 있습니다.
객체 인스턴스를 생성하고, 그 참조값을 전달해서 연결됩니다. 의존 관계 주입을 사용하면 클라이언트 코드를 변경하지 않고, 클라이언트가 호출하는 대상의 타입 인스턴스를 변경할 수 있습니다. 정적인 클래스 의존관계에서는 어떤 객체가 주입될 지 알기가 힘들기 때문에 애플리케이션 실행 시점에 실제 생성된 객체 인스턴스의 참조가 연결된 의존관계
IoC 컨테이너 , DI 컨테이너DI 컨테이너는 Dependency Injection 컨테이너로, 객체 간의 의존성을 주입하는 기능을 담당합니다. DI 컨테이너는 IoC 컨테이너의 일부로, 객체가 필요로 하는 의존성을 외부에서 주입해주는 역할을 합니다. 즉, 객체가 직접 의존하는 객체를 생성하고 관리하는 대신 DI 컨테이너에게 의존성을 위임하여 객체 간의 결합을 낮추고 유연한 코드를 작성할 수 있습니다.
Spring Framework에서는 ApplicationContext라는 IoC/DI 컨테이너를 제공합니다. ApplicationContext는 애플리케이션의 빈(Bean) 객체를 생성하고 관리하며, 의존성 주입을 수행합니다. 개발자는 ApplicationContext를 사용하여 필요한 빈을 가져오고, 의존성을 주입받을 수 있습니다.
AppConfig처럼 객체를 생성하고 관리하면서 의존관계를 연결해 주는 것을 IoC 컨테이너 또는 DI 컨테이너라고합니다. 의존관계 주입에 초점을 맞추어 최근에는 주로 DI 컨테이너라고 하며, 어셈블러, 오브젝트 팩토리 등으로 불리기도 합니다.
//AppConfig에 MemberService와 OrderServive의 역할은 잘 보여지지만 MemberRepository와 DiscountPolicy의 역할을 같이 구현
//아래와 같은 코드 변경의 장점은 각 메서드의 역할명만 보아도 역할을 알 수 있으며, 역할과 구현 클래스들을 한눈에 알 수 있습니다.
//애플리케이션 전체 구성이 어떻게 되어있는지 빠르게 파악이 가능
public class AppConfig {
//↓ 클라이언트 (주문생성 -회원 ID)
1. public MemberService memberService() {
return new MemberServiceImple(memberRepository());
}
//↓ 회원 저장소 역할 (메모리 회원 저장소 / DB 회원 저장소)
2. public MemberRepository memberRepository() {
return new MemoryMemberRepository();
}
//↓ 주문 서비스 역할 (회원 조회 / 할인 적용)
3. public OrderService orderService() {
return new OrderServiceImpl(memberRepository(), discountPolicy());
}
//↓ 할인 정책 역할 (정액 할인 정책 / 정률 할인 정책)
4. public DiscountPolicy discountPolicy() {
// return new FixDiscountPolicy();
return new RateDiscountPolicy();
}
}
스프링에서의 관심사의 분리는 소프트웨어 개발에서 중요한 개념 중 하나입니다. 관심사의 분리는 코드의 유지보수성, 재사용성, 테스트 가능성 등을 향상시키는 방법으로, 코드를 모듈화하여 각 모듈이 특정한 역할과 책임을 갖도록 하는 것을 의미합니다.
스프링에서의 관심사의 분리는 주로 다음과 같은 방식으로 이루어집니다:
의존성 주입 (Dependency Injection)
의존성 주입은 객체 간의 의존성을 외부에서 주입하는 방식으로, 객체 간의 결합도를 낮춥니다. 이를 통해 각각의 객체는 자신이 수행해야 할 기능에만 집중할 수 있으며, 객체 간의 의존성을 명확하게 분리할 수 있습니다.
제어 역전 (Inversion of Control)
제어 역전은 객체의 생명주기와 의존성 관리를 프레임워크가 담당하도록 하는 개념입니다. 스프링은 제어 역전을 통해 객체의 생성, 관리, 소멸 등의 생명주기를 관리하고, 필요한 의존성을 주입합니다. 이를 통해 개발자는 객체의 생성과 의존성 관리에 대한 부분을 신경쓰지 않고 핵심 비즈니스 로직에 집중할 수 있습니다.
관점 지향 프로그래밍 (Aspect-Oriented Programming, AOP)
AOP는 애플리케이션의 핵심 로직과 관련 없는 부가적인 기능들을 모듈화하여 분리하는 방식입니다. 예를 들어, 로깅, 트랜잭션 관리, 보안 등과 같은 부가적인 기능을 각각의 핵심 로직에서 분리하여 관리합니다. 이를 통해 핵심 로직의 코드는 더욱 간결해지고, 부가적인 기능은 별도의 모듈로 분리하여 관리할 수 있습니다.
위의 방법들을 활용하여 관심사를 분리하면 코드의 가독성과 유지보수성을 높일 수 있으며, 코드의 재사용성과 테스트 가능성도 향상시킬 수 있습니다. 또한, 각각의 모듈이 독립적으로 개발 및 테스트될 수 있어 개발 프로세스를 효율적으로 관리할 수 있습니다.
//OrderService 인터페이스를 구현해 줄 코드!
//OrderService는 DisCountPolicy가 변경되더라도 아무런 영향을 받지 않음
public class OrderServiceImpl implements OrderService{
private final MemberRepository memberRepository = new MemoryMemberRepository();
//아래와 같이 odreServiceImpl에서 discountPolicy를 직접 객체를 생성해서 구체적으로 작성하게 되면서 DIP를 위반하게 됩니다.
//private final DiscountPolicy discountPolicy = new FixDiscountPolicy();
//private final DiscountPolicy discountPolicy = new RateDiscountPolicy();
private DiscountPolicy discountPolicy;
//선언을 위와같이만 변경해준다면, 인터페이스에만 의존하게 됩니다. 주문을 만들어서 반환을 해주면 해당 파일의 실행이 종료됨
@Override
public OrderDTO createOrder(Long memberId, String itemName, int itemPrice) {
Member member = memberRepository.findById(memberId);
int discountPrice = discountPolicy.discount(member, itemPrice);
return new OrderDTO(memberId, itemName, itemPrice, discountPrice);
}
}
👉 관심사의 분리가 필요 ! AppConfig의 등장
애플리케이션의 전체 동작 방식을 구성(config)하기 위해, 구현 객체를 생성하고, 연결하는 책임을 갖는 별도의 설정 클래스를 만들자.
AppConfig
public class AppConfig {
//AppConfig를 통해서 memberService를 호출해서 사용하게 되는데 , return 값인 MemberServiceImpl 객체의 구현체가
//생성이 되는데, 그 때, MemoryMemberRepository가 매개변수로 전달되게됩니다. 임플로!
public MemberService memberService() {
return new MemberServiceImple(new MemoryMemberRepository());
//MemberServiceImple는 new MemoryMemberRepository 객체를 생성 후 참조 값을 받음
}
//AppConfig를 통해서 orderService를 조회하면 OrderServiceImpl이 반환되는데,
//그 안에 MemoryMemberRepository와 FixDiscountPolicy가 매개변수로 담겨져서 반환됩니다.
public OrderService orderService() {
return new OrderServiceImpl(new MemoryMemberRepository(),
new FixDiscountPolicy());
이러한 방식을 생성자를 통해 주입한다고 표현합니다
}
}
OrderServiceImpl
//OrderService 인터페이스를 구현해 줄 코드!
//OrderService는 DisCountPolicy가 변경되더라도 아무런 영향을 받지 않음
public class OrderServiceImpl implements OrderService{
//인터페이스에만 의존하도록 수정되어 DIP를 지킬 수 있음
private final DiscountPolicy discountPolicy;
private final MemberRepository memberRepository;
public OrderServiceImpl(MemberRepository memberRepository, DiscountPolicy discountPolicy ) {
this.memberRepository = memberRepository;
this.discountPolicy = discountPolicy;
}
@Override
public OrderDTO createOrder(Long memberId, String itemName, int itemPrice) {
Member member = memberRepository.findById(memberId);
int discountPrice = discountPolicy.discount(member, itemPrice);
return new OrderDTO(memberId, itemName, itemPrice, discountPrice);
}
}
설계 변경으로 MemberServiceImpl는 MemoryMemberRepository에 의존하지 않고 MemberServiceRepository 인터페이스만 의존합니다.
MemberServiceImpl의 입장에서 생성자를 통해 어떤 구현객체가 들어올지 (주입될 지)는 알 수 없으며, 어떤 구현 객체를 주입할 지는 오직 외부(AppConfig)에서 결정됩니다.
MemberServiceImpl은 “의존관계에 대한 고민은 외부” 에 맡기고 “실행에만 집중” 가능
package Spring.core;
public class AppConfig {
//↓ 클라이언트 (주문생성 -회원 ID)
public MemberService memberService() {
return new MemberServiceImple(memberRepository());
}
//↓ 회원 저장소 역할 (메모리 회원 저장소 / DB 회원 저장소)
private MemberRepository memberRepository() {
return new MemoryMemberRepository();
}
//↓ 주문 서비스 역할 (회원 조회 / 할인 적용)
public OrderService orderService() {
return new OrderServiceImpl(memberRepository(),
discountPolicy());
}
//↓ 할인 정책 역할 (정액 할인 정책 / 정률 할인 정책)
public DiscountPolicy discountPolicy() {
return new FixDiscountPolicy();
}
}
📄 새로운 구조와 할인 정책 적용
정액 할인 정책을 정률 할인 정책으로 변경해보자! 앞서 작성해둔 AppConfig의 등장으로 애플리케이션이 크게 사용 영역과 객체를 생성하고 구성(Configuration) 하는 영역으로 분리되었습니다.
AppConfig에서 할인 정책을 담당하는 구현부를 FixDiscountPolicy → RateDiscountPolicy로 변경을 진행하였습니다. 할인 정책이 변경되더라도 구성 영역인 AppConfig만 영역을 받고, 사용 영역은 전혀 영향을 받지 않을것입니다.
구성영역은 당연히 변경이 진행됩니다. 구성 역할을 담당하는 AppConfig를 애플리케이션이라는 공연의 기획자로 생각하면 간단합니다. 공연 기획자(=AppConfig)는 공연 참여자인 구현 객체들 (출연자)을 모두 알아야 합니다.
//↓ AppConfig 클래스의 discopuntPolicy 메서드의 리턴 값만 정률 할인 정책은
//RateDiscountPolicy()로 변경해주면 가능하다. 다른 구현체에게는 (사용영역에 있는) 영향이 없습니다.
public DiscountPolicy discountPolicy() {
return new FixDiscountPolicy();
}
JPA(Java Persistence API)는 Java 애플리케이션과 관계형 데이터베이스를 매핑하고 조작하기 위한 자바 ORM(Object-Relational Mapping) 표준입니다. JPA는 객체 지향 프로그래밍과 관계형 데이터베이스 간의 불일치를 해결하기 위해 개발되었습니다.
JPA는 개발자가 SQL 쿼리를 직접 작성하지 않고도 객체를 데이터베이스에 영속적으로 저장, 검색, 수정, 삭제할 수 있는 기능을 제공합니다. JPA는 데이터베이스 테이블과 자바 객체 사이의 매핑을 자동으로 처리하고, 객체 지향적인 방식으로 데이터베이스 작업을 수행할 수 있도록 도와줍니다.
JPA의 주요 특징과 기능은 다음과 같습니다:
객체-관계 매핑 : JPA는 자바 객체와 데이터베이스 테이블 간의 매핑을 자동으로 처리합니다. 어노테이션 기반의 매핑 설정을 통해 객체의 필드와 데이터베이스 컬럼을 매핑하고, 관계를 설정할 수 있습니다.
영속성 관리 : JPA는 객체의 영속성을 관리하여 객체의 상태 변경을 추적하고, 적절한 시점에 데이터베이스에 반영합니다. 변경 감지 기능을 통해 객체의 변경 사항을 자동으로 감지하고, 트랜잭션 커밋 시점에 변경 내용을 데이터베이스에 반영합니다.
JPQL(Java Persistence Query Language) : JPA는 객체 지향적인 쿼리 언어인 JPQL을 제공합니다. JPQL은 SQL과 유사한 문법을 가지며, 객체를 대상으로 쿼리를 작성할 수 있습니다. JPQL은 데이터베이스에 독립적인 쿼리를 작성할 수 있어서, 여러 종류의 데이터베이스에서 동일한 쿼리를 실행할 수 있습니다.
트랜잭션 관리 : JPA는 트랜잭션을 지원하여 여러 개의 데이터베이스 작업을 하나의 논리적인 작업 단위로 묶을 수 있습니다. 트랜잭션을 사용하여 데이터의 일관성과 안전성을 보장할 수 있습니다.
성능 최적화 : JPA는 지연 로딩(Lazy Loading)과 캐시 기능을 제공하여 데이터베이스 조회 성능을 최적화할 수 있습니다. 지연 로딩은 필요한 시점에 연관된 객체를 로딩하여 불필요한 데이터베이스 조회를 최소화합니다.
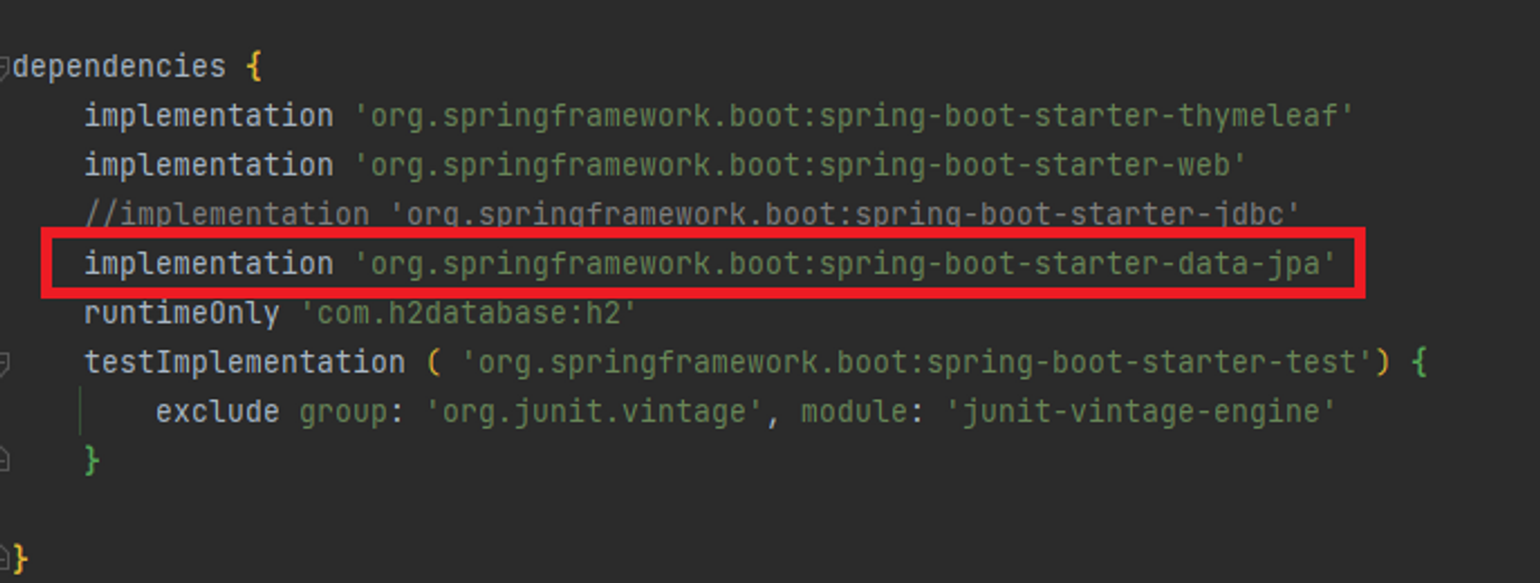
먼저 JPA를 사용하기 위해서는 라이브러리를 다운받거나 설정해주어야 하는 것들이 있습니다. 먼저 build.gradle 에서 dependency에서 data-jpa 라이브러리를 입력하여 다운받아야합니다. 작성하게 되면 오른쪽 상단에 그래들을 새로고침해주는 코끼리모양의 버튼이 생기는데 해당 버튼을 클릭하여 dependency 업데이트를 진행합니다.
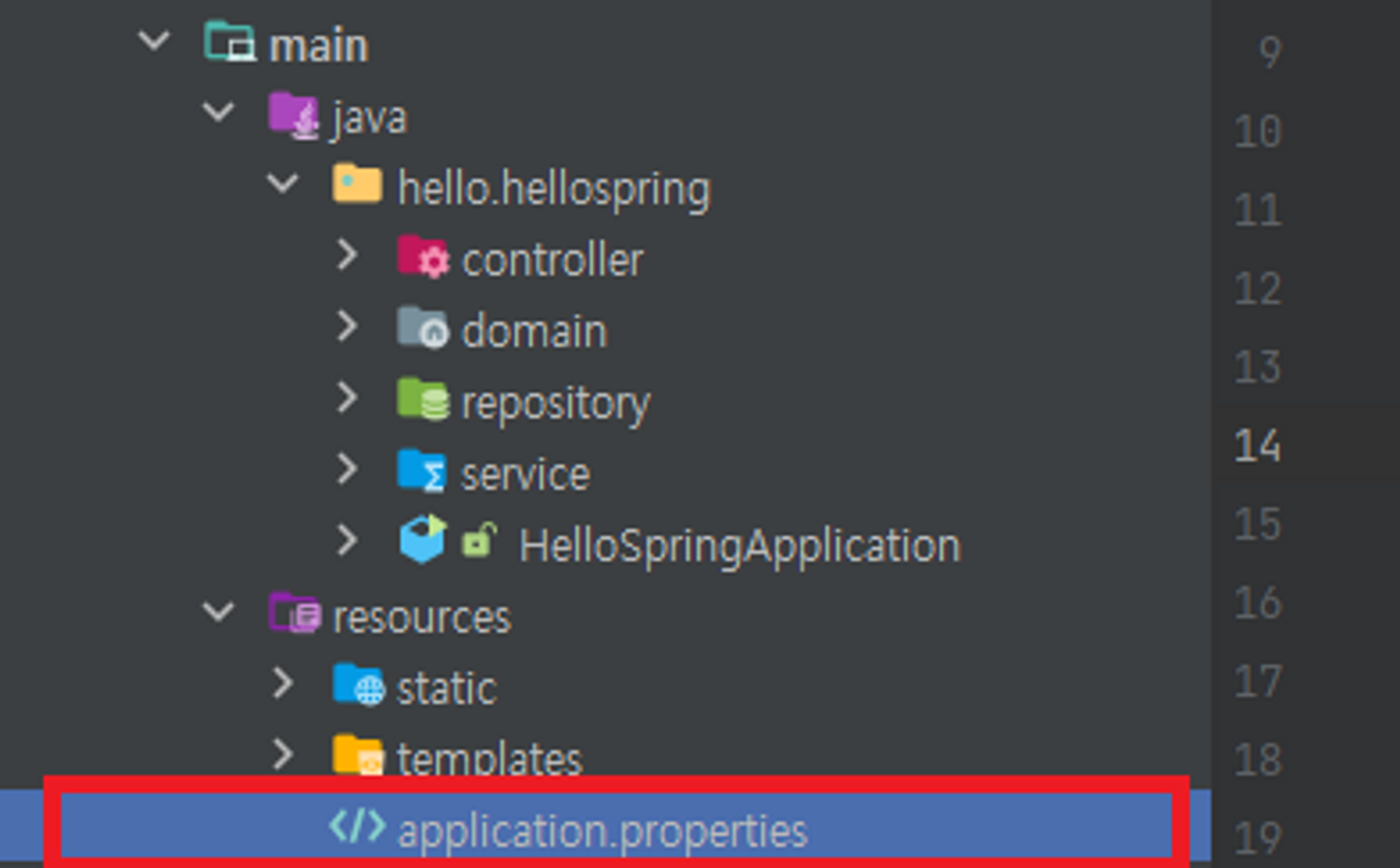
그리고 resources 내의 application.properties로 이동하여 jpa 관련 설정을 작성 후 저장해주시면 됩니다.
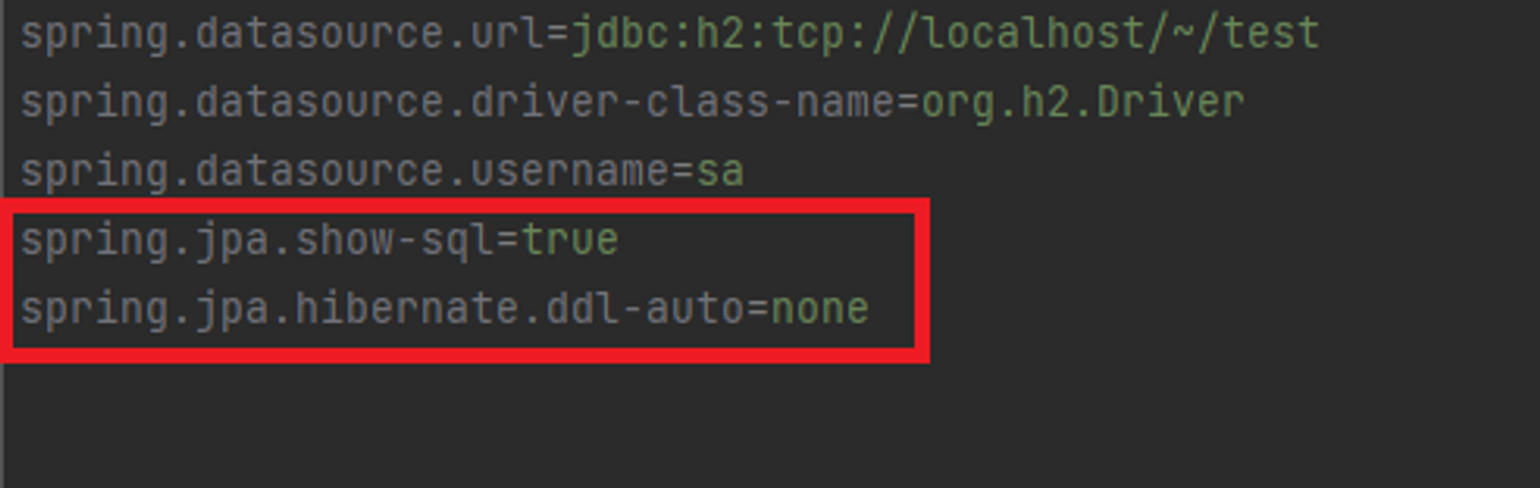
spring.jpa.show-sql=true 로 작성하면 jpa가 전달해주는 sql 데이터를 볼 수 있습니다. spring.jpa.hibernate.ddl-auto=none 를 작성하면 객체를 이용하여 테이블도 자동으로 생성해주는데, 자동으로 생성하는 기능은 끄고 작성할 예정입니다. 만약 none을 create로 작성 후 저장한다면 자동으로 테이블 생성도 가능합니다.
package hello.hellospring.domain;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
//jpa를 사용하려면 Entity를 맵핑해주어야 함
//Entity 어노테이션을 입력하게되면 아래의 멤버 변수는 jpa가 관리하는 멤버변수로 여겨짐
@Entity
public class Member {
//PK를 맵핑해주어야 합니다 H2 db에서 sql insert 문을 작성하면 db가 id를 자동으로 생성 / 이런 상황은 @GeneratedValue (strategy = GenerationType.IDENTITY) 이렇게 작성필요
@Id
@GeneratedValue (strategy = GenerationType.IDENTITY)
private Long id;
private String name;
//현재 db의 value의 컬럼이름은 name이라 그대로 두어도 되지만
//만약 username이라면 @Column(name = "username") 이라고 입력
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
package hello.hellospring.repository;
import hello.hellospring.domain.Member;
import org.hibernate.annotations.common.reflection.XMember;
import javax.persistence.EntityManager;
import java.util.List;
import java.util.Optional;
public class JpaMemberRepository implements MemberRepository {
//jpa는 EntityManager로 모든 동작이 진행됩니다.
//jpa 라이브러리를 다운받으면서 EntityManager를 자동으로 생성
private final EntityManager em;
public JpaMemberRepository(EntityManager em) {
this.em = em;
}
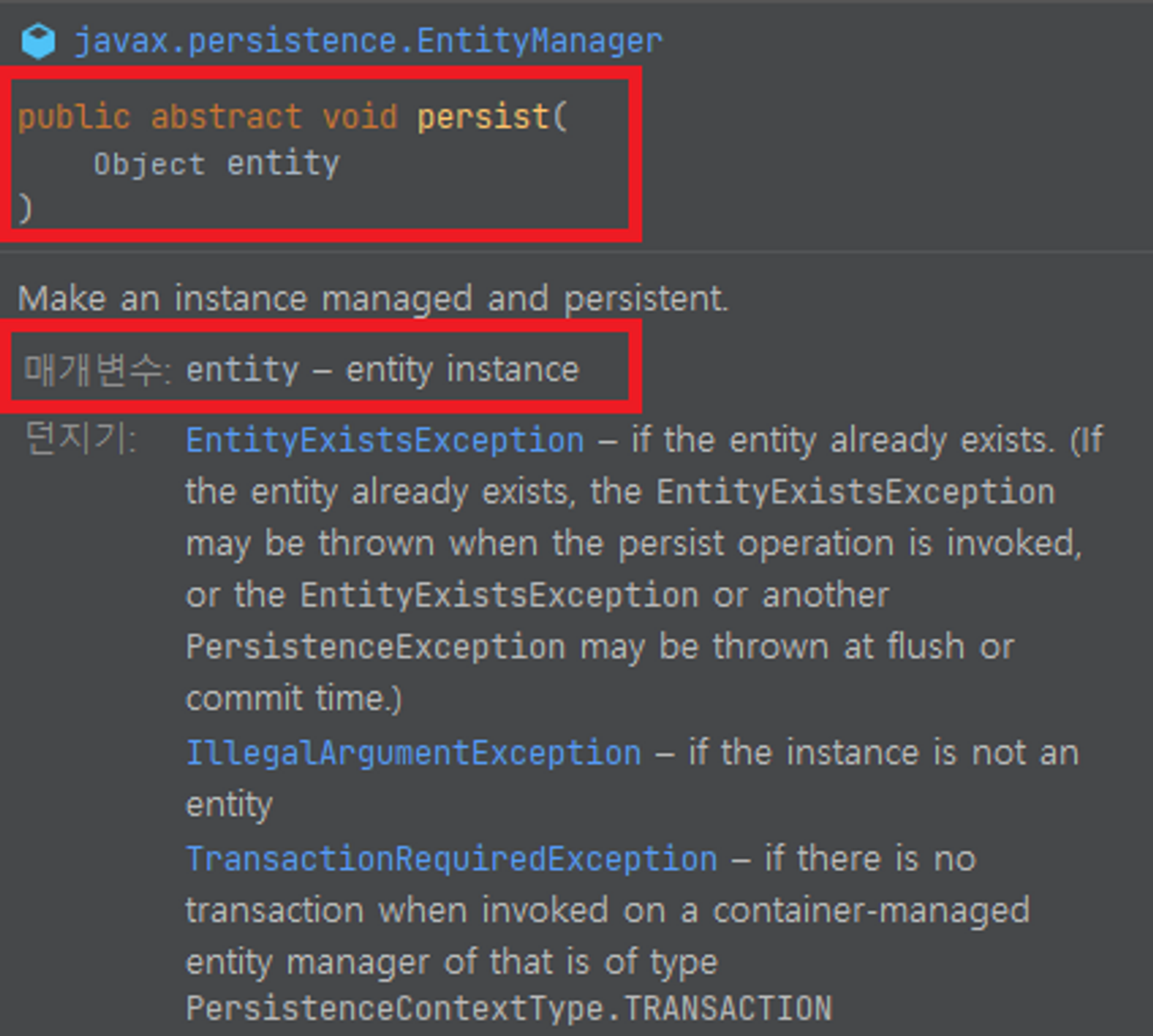
//↓ save 메서드는 아래와 같이만 작성해주면 jpa가 인서트 쿼리를 전부 만든 후 DB에 넘겨주고 setId까지 전부 진행을 해줌
//1개의 데이터를 저장하거나 찾는 코드에는 pk기반으로 작성이 가능
@Override
public Member save(Member member) {
em.persist(member);
return member;
}
//↓ find 메서드는 EntityManger 안에 em.find()로 매개변수로 조회할 타입과 식별자를 입력해주면 조회 가능
//return에는 Optional로 반환하고, 값이 없을 수도 있기 때문에 ofNullable()사용
//1개의 데이터를 저장하거나 찾는 코드에는 pk기반으로 작성이 가능
@Override
public Optional<Member> findById(Long id) {
Member member = em.find(Member.class, id);
return Optional.ofNullable(member);
}
//findByName 같은 경우에는 JPQL이라는 객체지향 언어를 사용
//1-2개의 데이터가 아닌 대량의 데이터를 활용하는 코드는 jpql을 작성해주어야 함
@Override
public Optional<Member> findByName(String name) {
List<Member> result = em.createQuery("select m from Member m where m.name = :name", Member.class).setParameter("name",name).getResultList();
return result.stream().findAny();
}
//1-2개의 데이터가 아닌 대량의 데이터를 활용하는 코드는 jpql을 작성해주어야 함
@Override
public List<Member> findAll() {
//"select m from Member m" 이 문장이 jpql이라는 쿼리 언어인데, 보통 테이블에서 sql을 출력하는데 여기선 select의 대상이 보통 *이나 id, name이 되는데 여기선 Member 엔티티 자체를 선택
//맵핑이 다 되어있고, 해당 쿼리문만 작성해주면 됨
return em.createQuery("select m from Member m", Member.class).getResultList();
//JPQL이라는 쿼리 언어
//객체를 대상으로 쿼리를 전달해주면 sql로 번역이 됨
}
}
브라우저와 원격프로그램을 실행하기 위한 (WAS) 브라우저에서 URL을 입력 후(ip주소) 호출을 한다면 해당 요청을 톰캣이 받아서 8080포트를 실행합니다.
2 . @Controller와 @RequestMapping이란 ?
@Controller와 @RequestMapping은 스프링 프레임워크에서 웹 애플리케이션의 컨트롤러를 정의하고 요청 매핑을 처리하는 데 사용되는 어노테이션입니다.
Controller : @Contoller 어노테이션은 클래스 레벨에 적용되며, 해당 클래스가 스프링 MVC의 컨트롤러임을 나타냅니다. 스프링은 이 클래스를 컨트롤러로 인식하고 요청을 처리하는 데 필요한 기능을 제공합니다.
RequestMapping (/hello) : @RequestMapping 어노테이션은 메서드 레벨에 적용되며, 해당 메서드가 특정 요청 경로와 연결되는 것을 나타냅니다. 즉, 클라이언트의 요청이 특정 URL 경로로 들어오면 해당 메서드가 실행되어 요청을 처리하게 됩니다.@RequestMapping 어노테이션은 여러 가지 속성을 가지고 있어서 경로 매칭, HTTP 메서드 제한, 요청 헤더나 파라미터 검증 등 다양한 기능을 설정할 수 있습니다.
package com.fastcampus.ch2;
import java.util.Calendar;
//년 월 일을 입력하면 요일을 알려주는 프로그램
public class YoilTeller {
public static void main(String[] args) {
//1. 입력
String year = args[0];
String month = args[1];
String day = args[2];
//문자열이니깐 숫자로 형변환을 함
int yyyy = Integer.parseInt(year);
int mm = Integer.parseInt(month);
int dd = Integer.parseInt(day);
//2. 작업
Calendar cal = Calendar.getInstance();
cal.set(yyyy,mm-1, dd);
//요일을 알아낼 수 있는데 1.일요일, 2. 월요일 ..
int dayOfweek = cal.get(Calendar.DAY_OF_WEEK);
char yoil = "일월화수목금토".charAt(dayOfweek);
//3.출력
System.out.println(year + "년" + month + "월" + day + "일은");
System.out.println(yoil + "요일입니다.");
}
}
java 인터프리터가 YoilTeller안의 메인 클래스를 호출하면 이후에 입력된 2022 12 2 값들을 가지고 배열을 만듭니다. String 배열이고 args[0] = 2022 , args[1] = 12 , args[2] = 2 로 담기면서 main 메서드 안에서 해당 배열이 사용이 가능합니다.
원격 프로그램을 브라우저로 URL을 입력하면 톰캣이 HttpServletRequest 객체를 만든 후 요청한 정보를 담습니다. HttpServeletRequest 변수(객체가 담긴 변수) 담은 후 매개변수로 메인메서드에 전달해줍니다.
3. HttpServeletRequest란 ❓
HttpServletRequest는 서블릿 컨테이너에서 HTTP 요청을 처리하기 위한 객체입니다. 이 객체를 통해 클라이언트로부터 온 HTTP 요청의 정보를 얻을 수 있습니다. HttpServletRequest는 javax.servlet.http 패키지에 포함되어 있습니다.
HttpServletRequest 객체는 클라이언트의 IP 주소, 쿠키 정보, 인증과 관련된 정보 등 다양한 HTTP 요청의 속성과 값을 얻을 수 있도록 메서드와 속성을 제공합니다. 이를 통해 서블릿에서 클라이언트의 요청을 분석하고 처리할 수 있습니다.
HttpServletRequest 객체는 HTTP 요청에 관련된 여러 가지 정보를 제공합니다. 몇 가지 중요한 메서드와 속성은 다음과 같습니다:
getScheme() : HttpServletRequest 인터페이스의 메서드로, 클라이언트의 요청에 사용된 프로토콜 스키마를 반환합니다. 프로토콜 스키마는 요청 URL의 앞부분에 위치한 프로토콜의 이름을 나타냅니다. 보통 http를 출력해줍니다.
getMethod() : HTTP 요청의 메서드를 반환합니다. 예를 들어, "GET", "POST", "PUT", "DELETE" 등의 값을 반환할 수 있습니다. getRequestURL() : 클라이언트가 보낸 요청의 URL을 반환합니다. getProtocol() : HTTP 프로토콜의 버전을 반환합니다. 예를 들어, "HTTP/1.1"과 같은 값을 반환할 수 있습니다. getParameter(String name) : 지정된 이름의 요청 매개변수 값을 반환합니다. HTTP 요청의 쿼리 문자열이나 폼 데이터에서 해당 이름을 가진 매개변수 값을 얻을 수 있습니다. getHeader(String name) : 지정된 이름의 HTTP 헤더 값을 반환합니다. 예를 들어, "User-Agent", "Content-Type" 등의 값을 얻을 수 있습니다. getSession() : 요청과 관련된 세션 객체를 반환합니다. 세션을 사용할 수 있는 경우 세션 객체를 반환하고, 세션을 사용할 수 없는 경우 null을 반환합니다.
getQueryString() 메서드는 HttpServletRequest 인터페이스의 메서드로, 요청 URL의 쿼리 문자열을 반환합니다. 쿼리 문자열은 URL의 물음표(?) 뒷부분에 위치하며, key=value 형식으로 매개변수와 값이 쌍으로 구성되어 있습니다.
getQueryString() 메서드를 사용하여 클라이언트가 전송한 요청의 쿼리 문자열을 분석하고 필요한 매개변수를 추출하는 등의 작업을 수행할 수 있습니다.
💡 동적 리소스 vs 정적 리소스
서버가 제공하는 리소스에는 크게 2가지가 있습니다. 동적 리소스(Dynamic Resources)와 정적 리소스(Static Resources)는 웹 개발에서 사용되는 개념입니다.
동적 리소스(Dynamic Resources) 동적 리소스는 클라이언트의 요청에 따라 서버에서 동적으로 생성되는 리소스를 말합니다. 서버 측 코드(예: PHP, Java, Python)를 사용하여 요청을 처리하고, 그에 따라 동적으로 HTML, 데이터베이스 쿼리 결과, API 응답 등을 생성합니다. 동적 리소스는 실행 할 때마다 결과가 변하며, 클라이언트의 요청에 따라 다양한 데이터를 가공하거나 개인화된 콘텐츠를 제공하는 데 사용됩니다. 예를 들어, 사용자가 로그인한 후에만 볼 수 있는 사용자 정보나 , 스트리밍 등이 동적으로 생성되는 웹 페이지가 동적 리소스에 해당합니다.
정적 리소스(Static Resources) 정적 리소스는 서버에 이미 저장되어 있는 파일이며, 서버에서 그대로 클라이언트에게 제공됩니다. 정적 리소스는 서버 측 코드의 개입 없이 클라이언트에게 제공되므로 속도가 빠르고 캐싱이 가능합니다. 주로 HTML, CSS, JavaScript, 이미지, 비디오, 오디오 파일 등이 정적 리소스에 해당합니다. 정적 리소스는 서버에 저장된 그대로의 내용을 클라이언트에 전달하므로, 클라이언트의 요청에 따라 동적으로 변하지 않습니다.
일반적으로 동적 리소스는 서버에서 동적으로 처리되어야 하는 데이터를 다루고, 정적 리소스는 클라이언트에게 제공되는 파일들을 나타냅니다. 동적 리소스는 서버의 로직에 의해 동적으로 생성되므로 처리 비용이 더 많이 소요되지만, 유연성과 개인화된 콘텐츠 제공이 가능합니다. 정적 리소스는 캐싱과 같은 기술을 활용하여 빠른 응답과 성능 향상을 도모할 수 있습니다.
클라이언트와 서버
클라이언트(Client)와 서버(Server)는 네트워크 환경에서 상호작용하는 컴퓨터 시스템입니다.
클라이언트(Client) 클라이언트는 사용자가 직접 사용하는 컴퓨터나 디바이스를 말합니다. 일반적으로 웹 브라우저(예: Chrome, Firefox)가 클라이언트의 역할을 수행합니다. 클라이언트는 사용자의 요청을 생성하고 서버로 전송합니다. 사용자는 클라이언트를 통해 서버에 요청을 보내고, 서버로부터 응답을 받아 화면에 결과를 표시합니다. 클라이언트는 사용자 인터페이스를 제공하며, 서버와의 통신을 위한 요청을 생성하고 응답을 받는 역할을 수행합니다.
서버(Server) 서버는 클라이언트의 요청을 받아 처리하고, 필요한 데이터나 리소스를 제공하는 컴퓨터나 시스템입니다. 서버는 클라이언트의 요청을 받아들여 해당 요청을 처리한 후, 클라이언트에게 응답을 보냅니다. 서버는 데이터베이스, 파일, 웹 페이지, 애플리케이션, API 등을 호스팅하고 관리하는 역할을 수행합니다. 서버는 네트워크를 통해 클라이언트와 통신하며, 클라이언트의 요청에 따라 동적으로 데이터를 생성하거나 처리할 수 있습니다.
클라이언트와 서버는 클라이언트-서버 아키텍처를 구성하는 두 가지 주요 구성 요소입니다. 클라이언트는 사용자와 상호작용하며 사용자 인터페이스를 통해 요청을 생성하고 응답을 표시합니다. 서버는 클라이언트의 요청을 받아 처리하고 필요한 데이터나 서비스를 제공하여 클라이언트에게 응답합니다. 이렇게 클라이언트와 서버가 함께 동작하여 웹 애플리케이션, 웹 서비스, 모바일 애플리케이션 등 다양한 네트워크 기반의 애플리케이션을 구현할 수 있습니다.
서버의 종류 ( 어떤 서비스를 제공하냐에 따라 달라집니다. Email server / File server / Web server
1대의 PC에 다양한 서버가 사용되고 있을 때, 클라이언트가 전송한 IP주소로는 어떤 서버에 요청한건 지 구분할 수 없기때문에 IP주소 뒤에 꼭 포트번호를 기입하여 구분합니다. 예를 들면 대표전화번호랑 비슷한 개념입니다. (ex) 1588-8888 → 내선번호(담당자 별로 내선번호를 갖고 있게 되는 경우) ip:port# / 웹 서버는 기본으로 : 80을 사용하기 때문에 기본적으로는 생략이 가능합니다.
서버가 포트와 연결(바인딩) 되어 있어야만 소통이 가능합니다 . 서버가 포트를 리스닝하고 있다고도 표현합니다. 포트번호는 0 ~ 1023까지는 전부 예약되어 있기 때문에 쓸 수 없지만 그 이후의 번호는 그 이후의 6만개정도를 사용 가능합니다.
웹 애플리케이션 서버 (WAS) 란?
Web Application Server (WAS)는 웹 애플리케이션을 실행하고 관리하는 서버 소프트웨어입니다. 웹 애플리케이션은 클라이언트(웹 브라우저)에서 서버로 요청을 보내고, 서버에서는 해당 요청에 대한 처리를 수행하여 결과를 클라이언트에게 제공합니다. 이러한 웹 애플리케이션을 실행하기 위해 Web Application Server가 필요합니다.
웹 애플리케이션 실행 환경 제공: Web Application Server는 웹 애플리케이션을 실행하기 위한 실행 환경을 제공합니다. 이 환경에는 필요한 라이브러리, 컴포넌트, 설정 파일 등이 포함됩니다. 또한, 다양한 프로그래밍 언어와 기술을 지원하여 개발자가 웹 애플리케이션을 개발할 수 있도록 합니다.
요청 처리 및 분배: Web Application Server는 클라이언트로부터 받은 요청을 처리하고, 애플리케이션으로 전달합니다. 요청에 따라 적절한 애플리케이션 컴포넌트(서블릿, JSP 등)를 호출하고, 처리 결과를 다시 클라이언트에게 반환합니다. 또한, 부하 분산을 위해 여러 웹 애플리케이션 인스턴스 간에 요청을 분배할 수 있습니다.
세션 및 상태 관리: 웹 애플리케이션은 클라이언트와 상호작용하면서 세션과 같은 상태 정보를 유지해야 할 수 있습니다. Web Application Server는 세션 관리를 지원하여 세션 데이터를 저장하고 관리합니다. 이를 통해 클라이언트와의 상태 유지 및 다중 서버 환경에서의 세션 공유가 가능해집니다.
데이터베이스 연동: 대부분의 웹 애플리케이션은 데이터베이스와 연동하여 데이터를 저장하고 조회합니다. Web Application Server는 데이터베이스와의 연결 관리를 수행하고, SQL 문 실행 및 결과 처리를 지원합니다. 이를 통해 웹 애플리케이션은 데이터베이스와 손쉽게 상호작용할 수 있습니다.
보안 및 인증: 웹 애플리케이션은 보안과 인증이 중요한 요소입니다. Web Application Server는 사용자 인증, 권한 관리, 데이터 암호화 등의 보안 기능을 제공합니다. 또한, 웹 애플리케이션의 취약점을 탐지하고 방어하기 위한 보안 설정을 제공합니다.
확장성과 가용성: Web Application Server는 대량의 요청을 처리하고, 다중 서버 구성을 통해 확장성과 가용성을 제공합니다. 여러 대의 서버를 클러스터로 구성하거나 로드 밸런서를 사용하여 부하를 분산할 수 있습니다. 이를 통해 웹 애플리케이션의 성능과 신뢰성을 향상시킬 수 있습니다.
주요한 Web Application Server로는 Apache Tomcat, Jetty, IBM WebSphere, Oracle WebLogic, JBoss 등이 있습니다. 이러한 서버는 다양한 웹 애플리케이션 프레임워크(예: Java Servlet, JavaServer Pages, Ruby on Rails, Django 등)와 함께 사용되어 웹 애플리케이션을 실행하고 관리합니다.