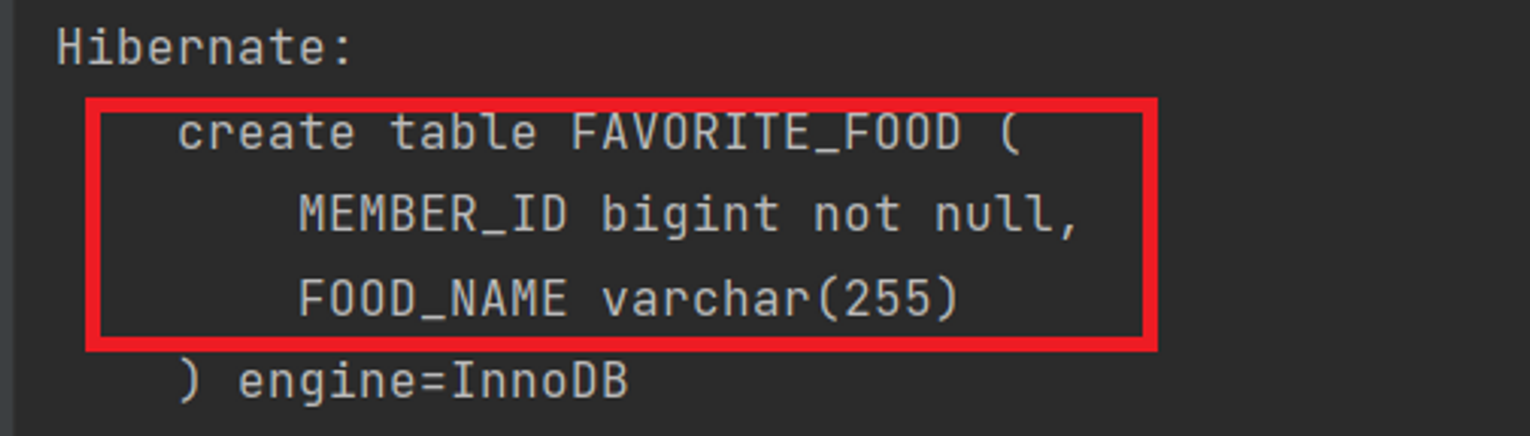
🎈 서블릿으로 회원 관리 웹 어플리케이션 만들기
👉 MemberForm 서블릿을 생성하여 회원을 등록할 수 있는 로직을 서블릿으로 작성
-> 회원 등록용 html form을 서블릿을 통해서 볼 수 있도록 설정
@WebServlet(name="memberFormServlet", urlPatterns = "/servlet/members/new-form")
public class MemberFormServlet extends HttpServlet {
private MemberRepository memberRepository = MemberRepository.getInstance();
-> 싱글톤이므로 new로 생성할 수 없기 때문에 getInstance()를 사용
@Override
protected void service(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
-> contentType과 Encoding을 설정
response.setContentType("text/html");
response.setCharacterEncoding("utf-8");
PrintWriter w = response.getWriter();
w.write("<!DOCTYPE html>\n" +
"<html>\n" +
"<head>\n" +
" <meta charset=\"UTF-8\">\n" +
" <title>Title</title>\n" +
"</head>\n" +
"<body>\n" +
"<form action=\"/servlet/members/save\" method=\"post\">\n" +
" username: <input type=\"text\" name=\"username\" />\n" +
" age: <input type=\"text\" name=\"age\" />\n" +
" <button type=\"submit\">전송</button>\n" +
"</form>\n" +
"</body>\n" +
"</html>\n");
}
}
위 코드에서 service 메서드는 HttpServlet 클래스의 메서드로, 클라이언트로부터 들어오는 모든 요청을 처리하는 역할을 합니다. 서블릿은 웹 애플리케이션에서 클라이언트와 서버 간의 통신을 담당하는 Java 클래스입니다.
서블릿은 HTTP 요청을 처리하여 동적인 웹 페이지를 생성하거나 데이터를 처리하는 데 사용됩니다.
HttpServlet 클래스는 GenericServlet 클래스를 상속받아서 만들어진 클래스로, HTTP 프로토콜을 사용하는 웹 애플리케이션에서 사용됩니다.
HttpServlet 클래스의 service 메서드는 HTTP 요청 방식(GET, POST, PUT, DELETE 등)에 따라 적절한 메서드(doGet, doPost, doPut, doDelete 등)를 호출하여 요청을 처리합니다.
예제에서 보여준 service 메서드는 클라이언트로부터 들어오는 모든 요청을 처리하고 있습니다. 먼저 response 객체를 이용하여 HTTP 응답을 설정합니다.
response.setContentType("text/html")은 응답으로 보낼 데이터의 MIME 타입을 설정하는 것이며, 여기서는 HTML 데이터를 전송한다는 의미입니다. response.setCharacterEncoding("utf-8")은 응답 데이터의 인코딩 방식을 설정합니다.
그리고 PrintWriter를 이용하여 HTML 형식의 응답 데이터를 작성합니다. 해당 HTML은 간단한 폼(form)을 생성하고, action 속성에 /servlet/members/save 경로로 요청을 보내도록 설정되어 있습니다.
save로 이동되어 회원이 저장된 코드를 볼 수 있는 로직을 작성해보겠습니다.
👉 SaveServlet을 생성하여 가입하는 회원의 데이터를 저장할 수 있는 로직을 서블릿으로 작성
@WebServlet(name="memberSaveServlet", urlPatterns = "/servlet/members/save")
public class MemberSaveServlet extends HttpServlet {
private MemberRepository memberRepository = MemberRepository.getInstance();
@Override
-> form 에서 전송된 데이터를 getParameter로 꺼낸 후 비즈니스 로직 작성을 위해 member를 만든 후 save 함
protected void service(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
System.out.println(" MemberSaveServlet.service ");
String username = request.getParameter("username");
int age = Integer.parseInt(request.getParameter("age"));
Member member = new Member(username, age);
memberRepository.save(member);
-> 결과는 html 형식으로 출력하기 위해 response.set으로 타입 설정 후, Printwriter객체로 작성
response.setContentType("text/html");
response.setCharacterEncoding("utf-8");
PrintWriter w = response.getWriter();
w.write("<html>\n" +
"<head>\n" +
" <meta charset=\"UTF-8\">\n" +
"</head>\n" +
"<body>\n" +
"성공\n" +
"<ul>\n" +
" <li>id="+member.getId()+"</li>\n" +
" <li>username="+member.getUsername()+"</li>\n" +
" <li>age="+member.getAge()+"</li>\n" +
"</ul>\n" +
"<a href=\"/index.html\">메인</a>\n" +
"</body>\n" +
"</html>");
}
}
🎈 JSP로 회원 관리 웹 어플리케이션 만들기
JSP(JavaServer Pages)는 동적 웹 페이지를 생성하는 데 사용되는 서버 사이드 기술입니다. JSP는 HTML 문서 안에 Java 코드를 삽입하여 웹 페이지를 동적으로 생성하고, 서버 측에서 로직을 처리할 수 있도록 지원합니다.
JSP는 Java 코드와 HTML 코드를 혼합하여 작성할 수 있으며, 서블릿과 매우 유사한 구조를 가지고 있습니다. JSP 파일은 서블릿 클래스로 변환되어 실행됩니다.
웹 애플리케이션이 요청을 받으면 JSP 컨테이너가 해당 JSP 파일을 처리하여 자바 코드를 생성하고, 이 코드를 컴파일하여 서블릿 클래스를 생성한 뒤 실행합니다.
JSP의 주요 특징은 다음과 같습니다:
- 간편한 웹 페이지 작성: JSP는 HTML과 유사한 태그를 사용하여 동적 웹 페이지를 작성할 수 있습니다. Java 코드는 <% %> 태그로 삽입하여 사용할 수 있으며, ${ } 태그를 이용하여 변수 값을 출력할 수 있습니다.
- 서버 사이드 로직 지원: JSP는 서버 사이드에서 데이터를 처리하고 동적으로 페이지를 생성하는데 사용됩니다. 사용자 입력을 받아 처리하거나 데이터베이스와 상호작용하는 등의 로직을 쉽게 구현할 수 있습니다.
- MVC 디자인 패턴과의 통합: JSP는 Model-View-Controller (MVC) 디자인 패턴과 함께 사용하기 쉽습니다. 데이터 처리는 서블릿이나 자바 빈(Java Bean)에서 처리하고, JSP는 뷰(View) 역할을 담당합니다.
JSP는 주로 웹 애플리케이션의 프론트엔드를 구현하는 데 사용되며, 동적인 컨텐츠를 생성하는 데 적합합니다. 그러나 비즈니스 로직이나 데이터 처리 로직과 같은 백엔드 부분은 주로 서블릿이나 다른 백엔드 기술을 활용하여 구현하는 것이 일반적입니다.
JSP를 사용하면 개발자들은 웹 프로그래밍을 좀 더 쉽게 시작할 수 있으며, 더 빠르게 동적인 웹 페이지를 구현할 수 있습니다.
그러나 복잡한 로직이나 규모가 큰 웹 애플리케이션을 개발할 때는 JSP의 한계를 극복하기 위해 프레임워크(Spring, Struts 등)나 템플릿 엔진(Thymeleaf, Freemarker 등)을 사용하는 경우가 많습니다.
💡 MVC 패턴
📋 MVC
MVC는 "Model-View-Controller"의 약자로, 소프트웨어 디자인 패턴 중 하나입니다. 웹 애플리케이션을 개발하는 데 널리 사용되며, 사용자 인터페이스와 비즈니스 로직을 분리하여 유지보수성과 확장성을 향상시키는 데 도움이 됩니다.
하나의 서블릿이나 JSP만으로 비즈니스 로직과 뷰 렌더링을 함께 처리하게 되면 너무 많은 역할을 가지고 있고, 유지보수가 어려워집니다.
비즈니스 로직을 호출하는 부분에 변경이 발생해도 해당 코드를 수정해야하고, UI를 변경할 일이 있어도 비즈니스 로직이 있는 파일을 수정해야 하는 번거로움이 발생합니다.
UI와 비즈니스로직의 변경의 라이프 사이클이 다르다는 점이 패턴으로 영역을 분리하게된 가장 큰 부분입니다. JSP 같은 뷰 템플릿은 화면을 렌더링하는 데 최적화 되어있기 때문에 해당 업무만 담당하는 것이 장 효과적입니다.
컨트롤러 : HTTP 요청을 받아서 파라미터를 검증하고, 비즈니스 로직을 실행합니다. 그리고 뷰에 전달할 결과 데이터를 조회해서 모델에 담습니다.
모델 : 뷰에 출력할 데이터를 담아둡니다. 뷰가 필요한 데이터를 모두 모델에 담아서 전달해주는 덕분에 뷰는 비즈니스 로직이나 데이터 접근을 몰라도 되고, 화면을 렌더링 하는 일에 집중할 수 있습니다.
- Model은 HttpServletRequest 객체를 사용한다. request는 내부에 데이터 저장소를 가지고 있는데,
request.setAttribute() , request.getAttribute() 를 사용하면 데이터를 보관하고, 조회할 수 있다.
뷰 : 모델에 담겨있는 데이터를 사용해서 화면을 그리는 일에 집중합니다 . 여기서는 HTML을 생성하는 부분입니다.
MVC 중 Controller 역할을 하는 class
package hello.servlet.web.servletmvc;
★ 컨트롤러의 역할
@WebServlet(name="mvcMemberFormServlet", urlPatterns = "/servlet-mvc/members/new-form")
public class MvcMemberFormServlet extends HttpServlet {
//mvc 패턴은 컨트롤러를 거쳐 뷰로 전달되기 때문에, memberForm을 보여주고 싶으려면 controller로 요청이 들어와야 함
@Override
protected void service(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
String viewPath = "/WEB-INF/views/new-form.jsp"; //해당 jsp 파일로 이동하는 경로를 viewPath로 만들어줌
RequestDispatcher dispatcher = request.getRequestDispatcher(viewPath);//컨트롤러에서 뷰로 이동할때 해당 경로로 이동할 수 있도록 해줌
dispatcher.forward(request, response); // 다른 서블릿이나 JSP로 이동할 수 있는 기능 , 서버 내부에서 다시 호출이 발생
// -> 리다이렉트로 이동하는 것이 아니라 서블릿 호출 -> jsp 호출 -> jsp에서 응답 만든 후 클라이언트에게 전송
}
}
1. 고객의 요청이 오면 service 메서드가 호출된 후 viewPath의 jsp 경로를 호출함
2. dispatcher.forward(request, response)로 서버 내부의 경로로 다시 호출
3. new-form.jsp로 이동한 후 패당 view가 클라이언트에게 전달되어 보여
리다이렉트는 실제 클라이언트(웹 브라우저)에 응답이 나갔다가, 클라이언트가 redirect 경로로 다시 요청합니다. 따라서 클라이언트가 인지할 수 있고, URL 경로도 실제로 변경되는 반면에 포워드는 서버 내부에서 일어나는 호출이기 때문에 클라이언트가 전혀 인지하지 못합니다.
View 역할을 하게 될 jsp
<%@ page contentType="text/html;charset=UTF-8" language="java" %>
<html>
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<!-- 상대경로 사용, [현재 URL이 속한 계층 경로 + /save] -->
<form action="save" method="post">
username: <input type="text" name="username" />
age: <input type="text" name="age" />
<button type="submit">전송</button>
</form>
</body>
</html
WEB-INF내부에 있는 파일들은 외부에서 직접적으로 불러와지는 것이 아니라
무조건 컨트롤러를 통해서 뷰가 호출될 수 있도록 설정할 수 있음 (WEB-INF 안에 넣어두면 됨!)
ex)localhost:8080/WEB-INF/views/new-form.jsp url을 작성한다고 해도 호출되지 않음
💥 mvc 패턴의 한계점
1. 복잡성 : MVC 패턴은 애플리케이션을 세 가지 기능으로 분리하므로 각각의 역할을 확실하게 정의하고 구현해야 합니다. 이로 인해 프로젝트가 커질수록 컨트롤러, 뷰, 모델 간의 관계가 복잡해질 수 있습니다.
2. 과도한 중재자 역할: 컨트롤러가 모든 요청을 중재하고 전달하므로 컨트롤러가 애플리케이션 내에서 중재자 역할을 맡게 됩니다. 이로 인해 컨트롤러가 비대해지고 유지보수가 어려워질 수 있습니다.
3. 높은 결합도: MVC 패턴은 각 기능을 분리하지만 여전히 서로 간에 의존성이 존재합니다. 이로 인해 하나의 기능을 변경할 때 다른 기능에도 영향을 미칠 수 있습니다.
4. 코드 중복: 여러 컨트롤러가 비슷한 기능을 구현해야 할 경우, 코드 중복이 발생할 수 있습니다. 이로 인해 유지보수가 어려워질 수 있습니다. View로 이동하는 코드가 항상 중복 호출되고, viewPath도 중복하여 작성되고 있습니다.
5. 테스트의 어려움 : 컨트롤러는 외부 요청을 처리하므로 단위 테스트가 어려울 수 있습니다. 특히, 컨트롤러가 다른 컴포넌트와 강하게 결합되어 있을 경우 테스트하기 어려울 수 있습니다. 테스트 코드 작성 시 HttpServletRequest , HttpServletResponse를 사용하는 코드는 테스트 케이스를 작성하기 어렵습니다.
6. 공통부분 처리 어려움 : 단순하게 공통 기능을 하나의 메서드로 생성하면 될 것 같지만, 결과적으로는 해당 메서드를 항상 호출해야하고, 실수로 호출하지 않으면 문제가되고 해당 메서드를 반복해서 호출하는 것 또한 중복으로 호출이 됩니다.
해당 문제점을 해결하기 위해 컨트롤러 호출 전에 먼저 공통 기능을 처리하는 프론트 컨트롤러(Front Controller) 패턴을 도입하여 해당 문제를 해결할 수 있습니다.
💡 MVC 프레임 워크 만들기
프론트 컨트롤러 패턴이란 ❓
프론트 컨트롤러 패턴은 웹 애플리케이션의 디자인 패턴 중 하나로, 클라이언트의 모든 요청을 하나의 컨트롤러로 집중시켜 처리하는 패턴입니다.
프론트 컨트롤러도 하나의 서블릿이며, 이 서블릿 하나로 클라이언트의 요청을 받아서 해당 요청에 대한 처리를 담당하는 컨트롤러로서의 역할을 수행합니다. 프론트 컨트롤러를 제외한 나머지 컨트롤러는 서블릿을 사용하지 않아도 됩니다.
일반적으로 웹 애플리케이션은 여러 개의 컨트롤러로 이루어져 있으며, 각 컨트롤러는 특정한 요청을 처리하는 역할을 합니다. 하지만 프론트 컨트롤러 패턴에서는 클라이언트의 모든 요청이 먼저 프론트 컨트롤러로 집중되고, 프론트 컨트롤러가 각 요청에 맞는 적절한 컨트롤러를 호출하여 요청을 처리합니다.
프론트 컨트롤러의 특징
- 중앙 집중화 : 모든 클라이언트 요청을 하나의 프론트 컨트롤러로 집중시킴으로써 애플리케이션의 구조를 단순화합니다. 이로 인해 각 컨트롤러가 클라이언트 요청을 직접 처리하는 것이 아니라 프론트 컨트롤러를 통해 처리됩니다.
- 공통 로직 처리 : 프론트 컨트롤러에서는 모든 요청에 공통적으로 필요한 로직을 처리할 수 있습니다. 예를 들어, 로그인 여부 확인, 권한 검사, 국제화 등의 작업을 한 곳에서 처리할 수 있습니다.
- 중복 코드 제거 : 프론트 컨트롤러에서 공통 로직을 처리하므로 다른 컨트롤러에서 해당 로직을 중복해서 작성할 필요가 없어집니다. 이로 인해 코드의 중복성을 줄이고 유지보수가 용이해집니다.
- 유연한 확장성 : 새로운 기능이나 요청이 추가되더라도 프론트 컨트롤러만 수정하면 됩니다. 기존의 컨트롤러를 수정할 필요가 없기 때문에 애플리케이션의 확장성이 좋아집니다.
- 코드 재사용성 : 공통 로직을 프론트 컨트롤러에서 처리하므로 다른 컨트롤러에서도 해당 로직을 재사용할 수 있습니다.
- 유지보수 용이성 : 프론트 컨트롤러 패턴을 사용하면 모든 요청이 한 곳에서 처리되기 때문에 유지보수가 용이해집니다. 추가 기능의 변경이나 버그 수정 등을 프론트 컨트롤러에서 처리하면 다른 컨트롤러의 코드를 건드릴 필요가 없습니다.
프론트 컨트롤러 패턴은 웹 애플리케이션의 구조를 더욱 효율적이고 유연하게 만들어주며, 중복 코드를 줄이고 보안을 강화하는 데에 도움이 됩니다. 스프링 웹 MVC의 DispatcherServlet이 FrontController 패턴으로 구현되어 있습니다.