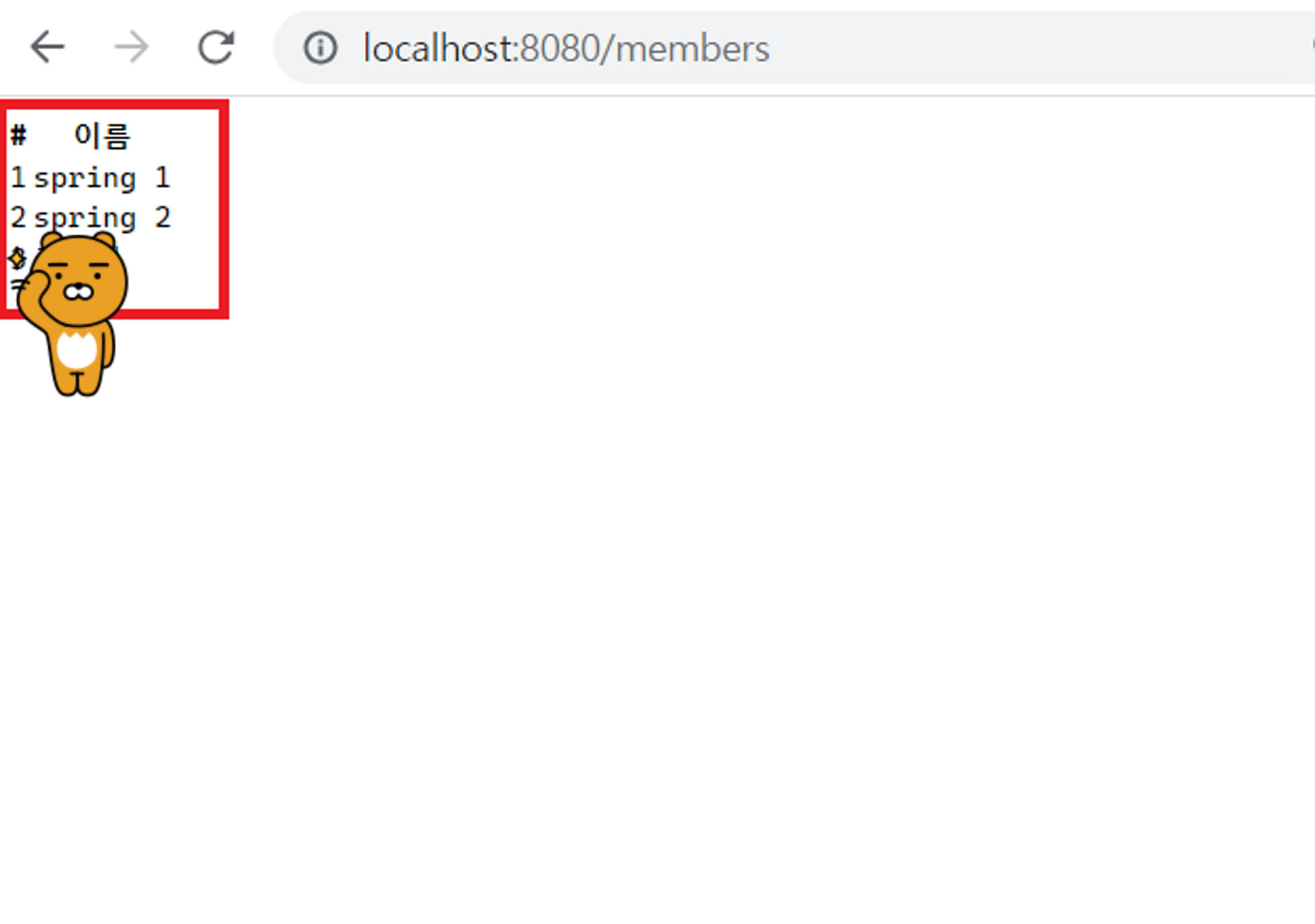
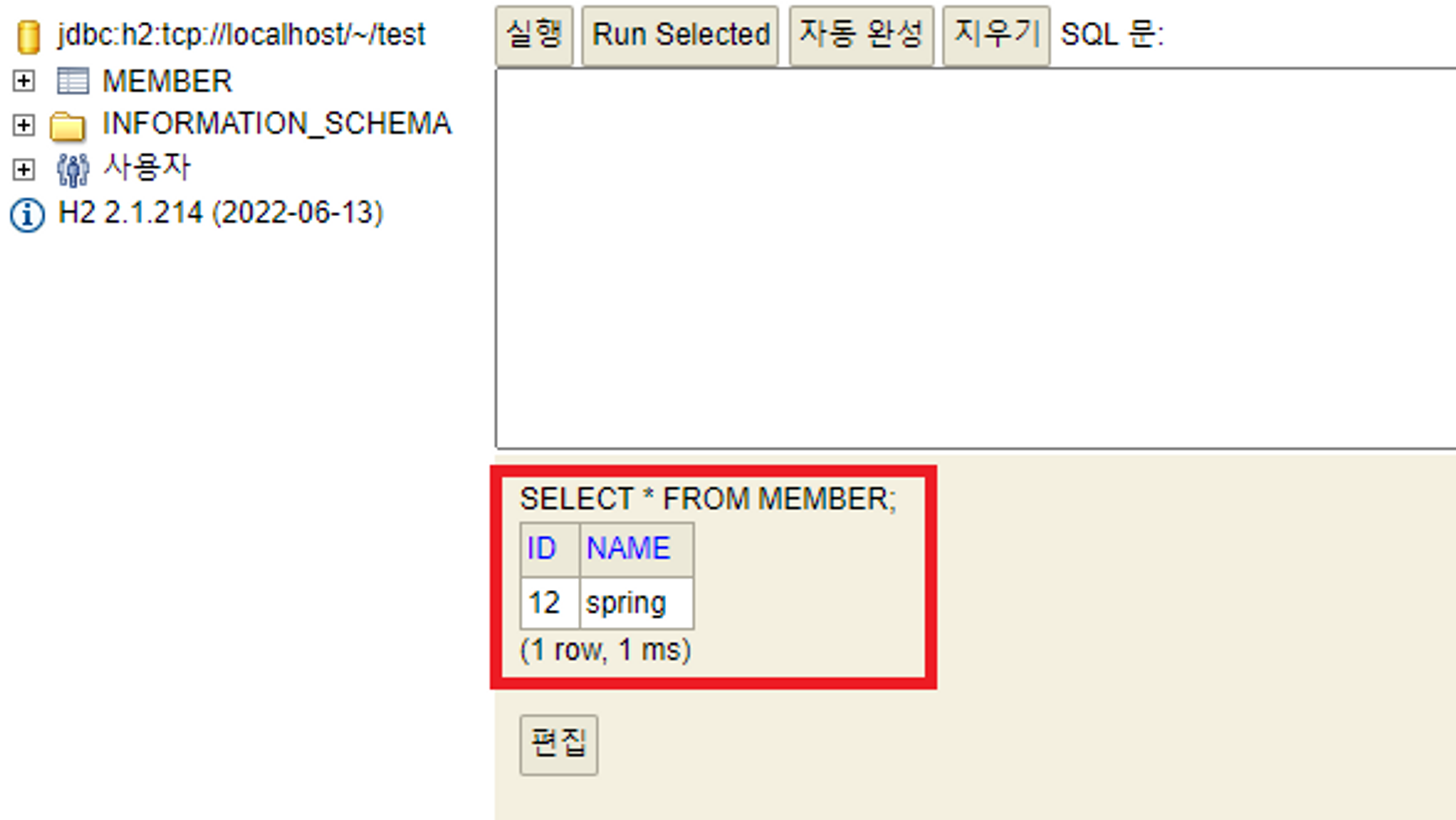
JPA란 ❓
JPA는 기존의 반복 코드는 물론이고, 기본적인 SQL도 JPA가 직접 만들
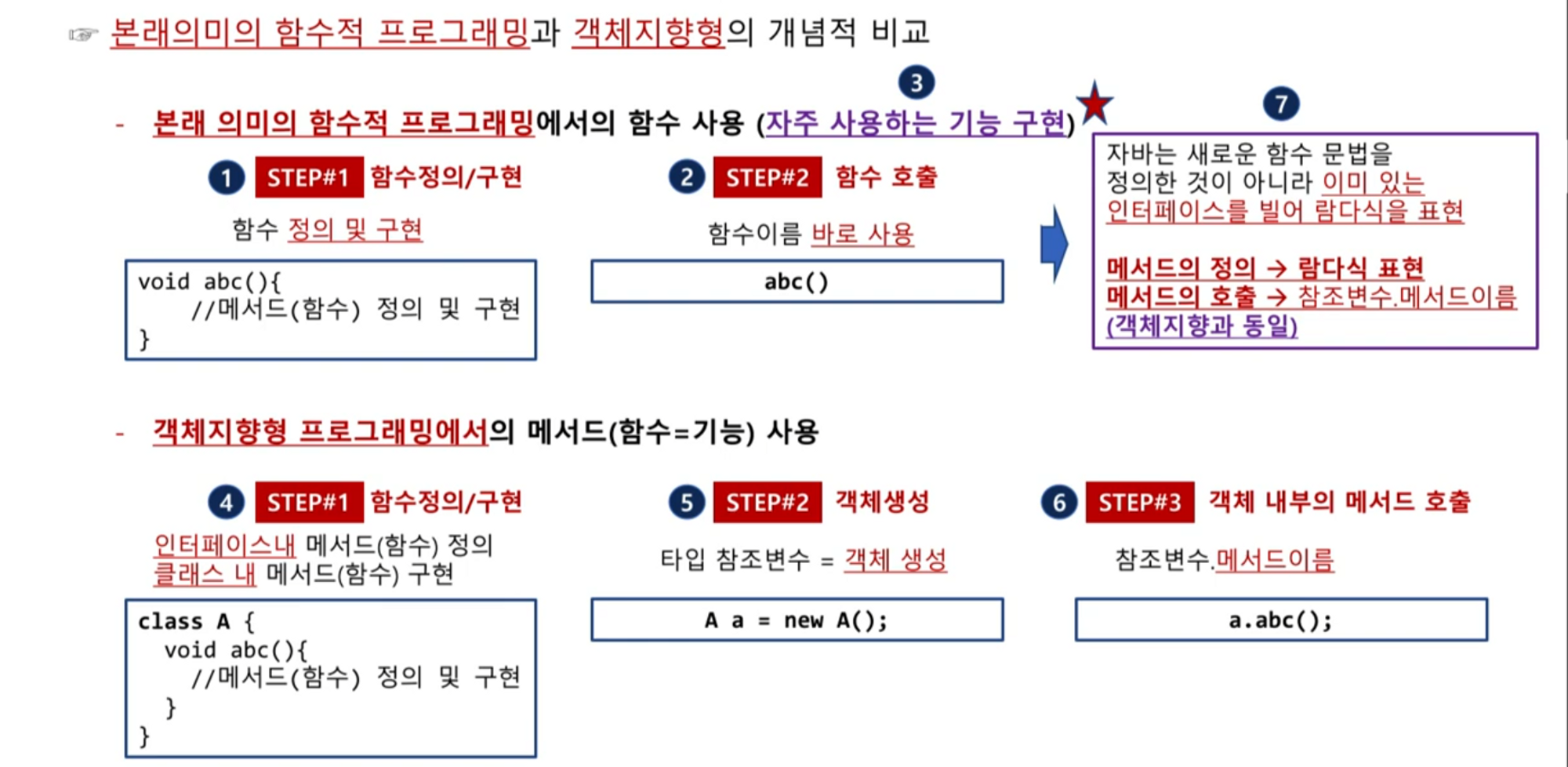
JPA(Java Persistence API)는 Java 애플리케이션과 관계형 데이터베이스를 매핑하고 조작하기 위한 자바 ORM(Object-Relational Mapping) 표준입니다. JPA는 객체 지향 프로그래밍과 관계형 데이터베이스 간의 불일치를 해결하기 위해 개발되었습니다.
JPA는 개발자가 SQL 쿼리를 직접 작성하지 않고도 객체를 데이터베이스에 영속적으로 저장, 검색, 수정, 삭제할 수 있는 기능을 제공합니다. JPA는 데이터베이스 테이블과 자바 객체 사이의 매핑을 자동으로 처리하고, 객체 지향적인 방식으로 데이터베이스 작업을 수행할 수 있도록 도와줍니다.
JPA의 주요 특징과 기능은 다음과 같습니다:
- 객체-관계 매핑 : JPA는 자바 객체와 데이터베이스 테이블 간의 매핑을 자동으로 처리합니다. 어노테이션 기반의 매핑 설정을 통해 객체의 필드와 데이터베이스 컬럼을 매핑하고, 관계를 설정할 수 있습니다.
- 영속성 관리 : JPA는 객체의 영속성을 관리하여 객체의 상태 변경을 추적하고, 적절한 시점에 데이터베이스에 반영합니다. 변경 감지 기능을 통해 객체의 변경 사항을 자동으로 감지하고, 트랜잭션 커밋 시점에 변경 내용을 데이터베이스에 반영합니다.
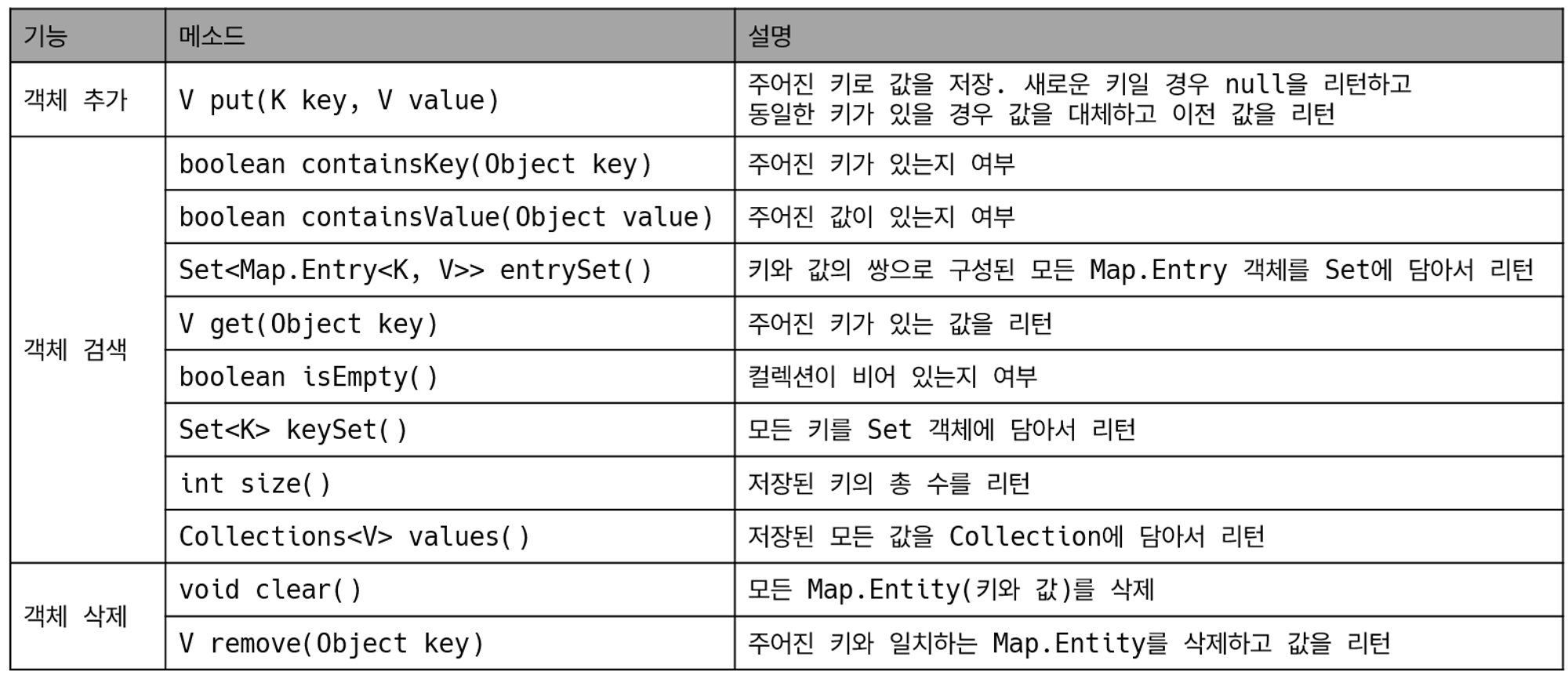
- JPQL(Java Persistence Query Language) : JPA는 객체 지향적인 쿼리 언어인 JPQL을 제공합니다. JPQL은 SQL과 유사한 문법을 가지며, 객체를 대상으로 쿼리를 작성할 수 있습니다. JPQL은 데이터베이스에 독립적인 쿼리를 작성할 수 있어서, 여러 종류의 데이터베이스에서 동일한 쿼리를 실행할 수 있습니다.
- 트랜잭션 관리 : JPA는 트랜잭션을 지원하여 여러 개의 데이터베이스 작업을 하나의 논리적인 작업 단위로 묶을 수 있습니다. 트랜잭션을 사용하여 데이터의 일관성과 안전성을 보장할 수 있습니다.
- 성능 최적화 : JPA는 지연 로딩(Lazy Loading)과 캐시 기능을 제공하여 데이터베이스 조회 성능을 최적화할 수 있습니다. 지연 로딩은 필요한 시점에 연관된 객체를 로딩하여 불필요한 데이터베이스 조회를 최소화합니다.
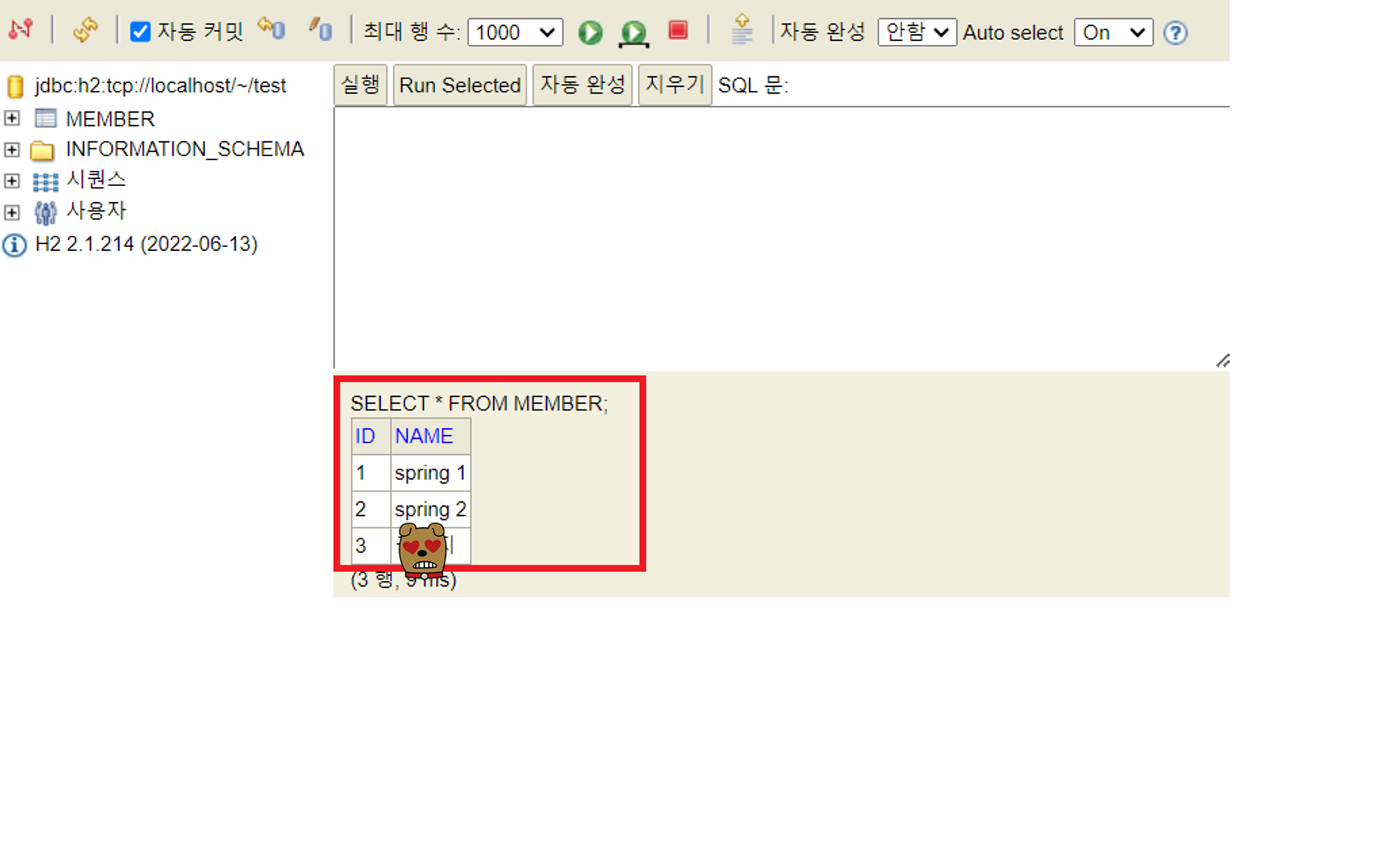
먼저 JPA를 사용하기 위해서는 라이브러리를 다운받거나 설정해주어야 하는 것들이 있습니다. 먼저 build.gradle 에서 dependency에서 data-jpa 라이브러리를 입력하여 다운받아야합니다. 작성하게 되면 오른쪽 상단에 그래들을 새로고침해주는 코끼리모양의 버튼이 생기는데 해당 버튼을 클릭하여 dependency 업데이트를 진행합니다.
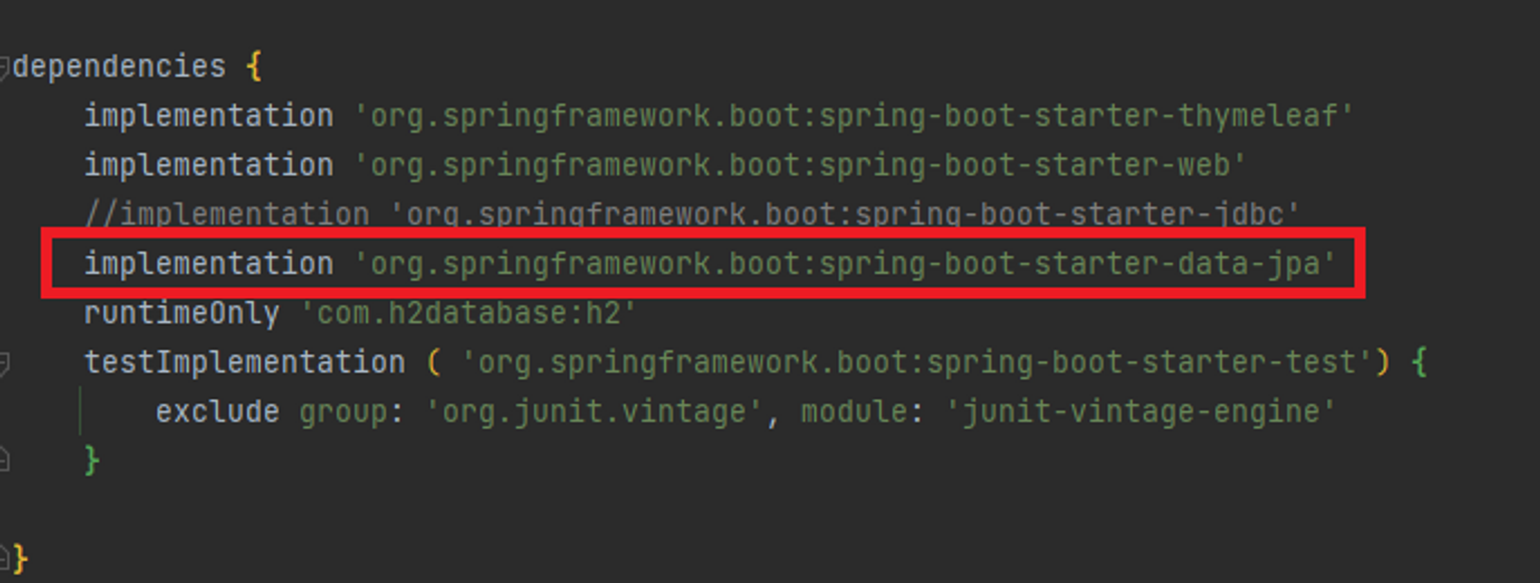
그리고 resources 내의 application.properties로 이동하여 jpa 관련 설정을 작성 후 저장해주시면 됩니다.

spring.jpa.show-sql=true 로 작성하면 jpa가 전달해주는 sql 데이터를 볼 수 있습니다. spring.jpa.hibernate.ddl-auto=none 를 작성하면 객체를 이용하여 테이블도 자동으로 생성해주는데, 자동으로 생성하는 기능은 끄고 작성할 예정입니다. 만약 none을 create로 작성 후 저장한다면 자동으로 테이블 생성도 가능합니다.


package hello.hellospring.domain;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
//jpa를 사용하려면 Entity를 맵핑해주어야 함
//Entity 어노테이션을 입력하게되면 아래의 멤버 변수는 jpa가 관리하는 멤버변수로 여겨짐
@Entity
public class Member {
//PK를 맵핑해주어야 합니다 H2 db에서 sql insert 문을 작성하면 db가 id를 자동으로 생성 / 이런 상황은 @GeneratedValue (strategy = GenerationType.IDENTITY) 이렇게 작성필요
@Id
@GeneratedValue (strategy = GenerationType.IDENTITY)
private Long id;
private String name;
//현재 db의 value의 컬럼이름은 name이라 그대로 두어도 되지만
//만약 username이라면 @Column(name = "username") 이라고 입력
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
package hello.hellospring.repository;
import hello.hellospring.domain.Member;
import org.hibernate.annotations.common.reflection.XMember;
import javax.persistence.EntityManager;
import java.util.List;
import java.util.Optional;
public class JpaMemberRepository implements MemberRepository {
//jpa는 EntityManager로 모든 동작이 진행됩니다.
//jpa 라이브러리를 다운받으면서 EntityManager를 자동으로 생성
private final EntityManager em;
public JpaMemberRepository(EntityManager em) {
this.em = em;
}
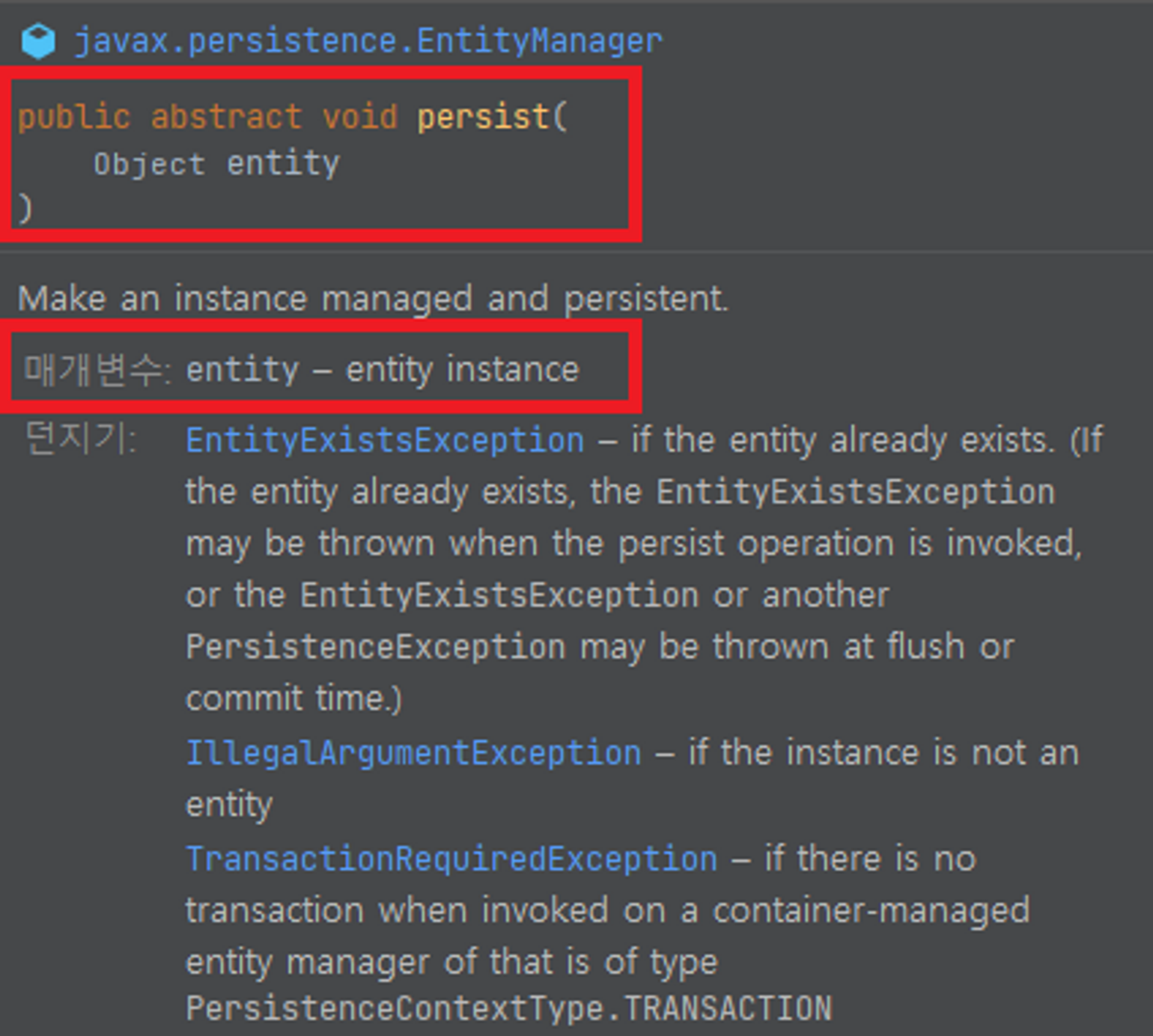
//↓ save 메서드는 아래와 같이만 작성해주면 jpa가 인서트 쿼리를 전부 만든 후 DB에 넘겨주고 setId까지 전부 진행을 해줌
//1개의 데이터를 저장하거나 찾는 코드에는 pk기반으로 작성이 가능
@Override
public Member save(Member member) {
em.persist(member);
return member;
}
//↓ find 메서드는 EntityManger 안에 em.find()로 매개변수로 조회할 타입과 식별자를 입력해주면 조회 가능
//return에는 Optional로 반환하고, 값이 없을 수도 있기 때문에 ofNullable()사용
//1개의 데이터를 저장하거나 찾는 코드에는 pk기반으로 작성이 가능
@Override
public Optional<Member> findById(Long id) {
Member member = em.find(Member.class, id);
return Optional.ofNullable(member);
}
//findByName 같은 경우에는 JPQL이라는 객체지향 언어를 사용
//1-2개의 데이터가 아닌 대량의 데이터를 활용하는 코드는 jpql을 작성해주어야 함
@Override
public Optional<Member> findByName(String name) {
List<Member> result = em.createQuery("select m from Member m where m.name = :name", Member.class).setParameter("name",name).getResultList();
return result.stream().findAny();
}
//1-2개의 데이터가 아닌 대량의 데이터를 활용하는 코드는 jpql을 작성해주어야 함
@Override
public List<Member> findAll() {
//"select m from Member m" 이 문장이 jpql이라는 쿼리 언어인데, 보통 테이블에서 sql을 출력하는데 여기선 select의 대상이 보통 *이나 id, name이 되는데 여기선 Member 엔티티 자체를 선택
//맵핑이 다 되어있고, 해당 쿼리문만 작성해주면 됨
return em.createQuery("select m from Member m", Member.class).getResultList();
//JPQL이라는 쿼리 언어
//객체를 대상으로 쿼리를 전달해주면 sql로 번역이 됨
}
}'[ BACKEND] > Spring' 카테고리의 다른 글
| [SPRING] IoC , DI , 스프링 컨테이너 (0) | 2023.07.17 |
|---|---|
| [SPRING] 관심사를 분리 ✅ (0) | 2023.07.14 |
| [SPRING] HTTP 요청과 응답 (1) | 2023.07.10 |
| [SPRING] 스프링 DB 접근 기술 (0) | 2023.07.08 |
| [SPRING] Spring Bean과 의존 관계 (0) | 2023.07.02 |